
- ディープラーニングを始めたいけど、何から手をつければいいのか分からない
- TensorFlowって聞いたことあるけど、どう使えばいいの?
- 難しそうで途中で挫折しそう…
こんな悩みを解決します。
Pythonでディープラーニングを始めるなら、TensorFlowがおすすめです。
TensorFlowとは、機械学習とディープラーニングのためのライブラリのこと。
TensorFlowは初心者でも扱いやすい設計になっており、手順通りに学べば実践的なモデル構築が可能です。
この記事では、Pythonを使ったTensorFlowの基本的な使い方について、わかりやすく解説します。
この記事を読めば、あなたもPythonとTensorFlowを使って、手書き数字を認識する基本的なディープラーニングモデルを自分で構築できるようになります。
TensorFlowとは

TensorFlowの概要
TensorFlowは、Googleが開発した機械学習とディープラーニングのためのライブラリです。
読み方は「テンソルフロー」です。
その名前は、「Tensor(テンソル)」と呼ばれる多次元配列データが、グラフ構造の中を「Flow(流れる)」ように計算が進むことに由来しています。
TensorFlowは、PythonやC言語など複数の言語に対応しています。
TensorFlowを使うことで、ニューラルネットワークの構築、学習、推論、評価、運用までを効率よく一貫して行うことができます。
TensorFlowは次の分野などで活用されています。
- 画像認識・画像処理
- 自然言語処理
- 音声認識・音声合成
- 時系列データ分析・予測
TensorFlowの主な特徴
TensorFlowの主な特徴は次のとおり。
- 柔軟性と拡張性
- 分散学習
- クロスプラットフォーム対応
- 豊富なツールとエコシステム
- 活発なコミュニティとドキュメント
柔軟性と拡張性
TensorFlowは、低レベルAPIから高レベルAPI(Keras)まで提供しています。そのため、研究レベルの複雑なモデル構築から、迅速なプロトタイピングまで、幅広いニーズに対応できます。
分散学習
TensorFlowでは大規模なデータセットや複雑なモデルを扱う際に、複数のCPUやGPU、TPU(Tensor Processing Unit)に計算を分散させ、学習時間を大幅に短縮できます。
クロスプラットフォーム対応
TensorFlowはサーバーやデスクトップ上だけでなく、多様な環境へのデプロイが可能です。
たとえば、TensorFlow Liteを使えばスマートフォンや組み込みデバイス上でモデルを実行でき、TensorFlow.jsを使えばWebブラウザ上で実行できます。
豊富なツールとエコシステム
TensorFlowには開発を支援する強力なツール群が充実しています。
これらを総称して「TensorFlowエコシステム」と呼びます。
- TensorFlow Extended (TFX):本番環境用のML/DLパイプライン構築ツール
- TensorFlow Hub:事前学習済みモデルのリポジトリ
- TensorFlow Lite:モバイルやIoTデバイス向けの軽量版
- TensorFlow.js:ブラウザやNode.js向けのJavaScriptライブラリ
- TensorBoard:学習過程などの可視化ツール
- TensorFlow Probability:確率的推論と統計的分析のためのライブラリ
活発なコミュニティとドキュメント
TensorFlowは世界中に多くのユーザーがいるため、豊富なドキュメントやチュートリアル、Q&Aフォーラムが存在しています。
TensorFlowを学習する中で、わからないことを解決しやすくなっています。
TensorFlow 1.xから2.xへの変更点
TensorFlowはバージョンアップを重ねており、特にTensorFlow 1.xから2.xへの移行では大きな変更がありました。主な変更点は以下のとおりです。
- Eager Execution(イーガー実行)のデフォルト化
- Kerasの標準API化
- APIの整理と簡略化
Eager Execution(イーガー実行)のデフォルト化
TensorFlow 1.xでは計算グラフを定義してからセッションで実行するスタイル「Define-and-Run」が主流でした。
TensorFlow 2.xではコードを記述した順に即座に実行されるスタイル「Define-by-Run」がデフォルトとなり、よりPythonicで直感的なコーディングとデバッグが可能になりました。
Kerasの標準API化
高レベルAPIであるKerasがTensorFlowの公式の標準APIとして統合されました。
これにより、モデル構築がより簡単かつ一貫性のある方法で行えるようになりました。
APIの整理と簡略化
古いAPIや冗長なAPIが整理され、より使いやすく、わかりやすい構造になりました。

この記事では、TensorFlow 2.xを前提として解説を進めます
Kerasとは
Keras(ケラス)は、TensorFlowを使いやすくするための高レベルAPIです。もともとは独立したライブラリでしたが、現在はTensorFlowに統合されています。
Kerasを使うことで、モデルの構築や学習、評価といったプロセスを簡潔なコードで記述できます。
低レベルな演算の詳細を意識することなく、ネットワークの層(レイヤー)を積み重ねるような直感的な方法でモデルを定義できるのが大きな特徴です。
ニューラルネットワーク・ディープラーニングの基礎
ニューラルネットワークとは
ニューラルネットワークは、人間の脳内のニューロンのつながりを模倣した数学モデルです。
主に入力層、隠れ層、出力層という3つの層で構成されています。
各層にはノード(ニューロン)があり、ノード間は重みを持った接続で結ばれています。
各ノードは入力値に重みを掛けて合計し、活性化関数を通して出力を決定します。
ディープラーニングとは
ディープラーニングは、多層(深い)ニューラルネットワークを使った機械学習手法です。
層を深くすることで、より複雑で抽象的な特徴をデータから自動的に学習することが可能になりました。
ディープラーニングは画像認識、自然言語処理、音声認識などの分野で、従来の機械学習手法を大幅に上回る精度を達成しています。
TensorFlowの使い方
ライブラリのインストール
TensorFlowをインストールしていない方は、下記コマンドをコマンドプロンプトで実行しましょう。
pip install tensorflowTensorFlowを使用するときは、仮想環境の使用がおすすめです。
仮想環境を使うと、プロジェクトごとに異なるバージョンのライブラリを使用でき、環境の衝突を避けられます。
仮想環境の作成例は次の通りです。
# 仮想環境の作成(仮想環境名は変更可能)
python -m venv tensorflow_env
# 仮想環境の有効化(Windows)
tensorflow_env\Scripts\activate
# TensorFlowのインストール
pip install tensorflow仮想環境については、こちらの記事で解説しています。
⇒ 【Python仮想環境】初心者でもできるvenvによる仮想環境作成方法を解説!
Google Colabでの使用
Google Colab(Google Colaboratory)は、ブラウザ上でPythonコードを実行できる無料の開発環境です。
Google ColabにはTensorFlowがプリインストールされているので、すぐに使用できます。
Google ColabはGPUも無料で使えるため、ディープラーニングを学ぶのに最適です。
Google Colabについては、こちらの記事で解説しています。
⇒ 【Google Colabの使い方】ブラウザ上のPython開発環境を解説!Google Driveへの連携方法も紹介
ライブラリの使用方法
TensorFlowを使用するときは下記のようにインポートしましょう。
TensorFlowは「tf」という別名でインポートします。
import tensorflow as tfKerasを使用する場合は、個別にインポートすることも可能です。
import tensorflow as tf
from tensorflow import kerasKerasを使うとき「tf.keras.」と書くか、「keras.」と書くかの違いです
TensorFlowの基本フロー
TensorFlowを使ったディープラーニングの基本的な流れは以下のとおりです。
- データの準備:学習データとテストデータを用意
- モデルの構築:ニューラルネットワークなどのモデルを設計
- モデルのコンパイル:損失関数とオプティマイザを設定
- モデルの学習:学習データを使ってパラメータを最適化
- モデルの評価:テストデータで性能を評価
- 予測の実行:新しいデータに対して予測を実施
- モデルの保存と読み込み:学習済みモデルを保存・再利用
TensorFlowの基本フローについて、手書き数字の画像データセットとして有名なMNISTを使い、解説します。
サンプルコード全体は次のとおり。
# インポート
import tensorflow as tf
import numpy as np
# MNISTデータセットの読み込み
# (x_train, y_train):学習データ(画像とラベル)
# (x_test, y_test):テストデータ(画像とラベル)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# データの正規化
x_train_scaled = x_train / 255.0
x_test_scaled = x_test / 255.0
# データ形状の確認
print("学習データの形状:", x_train_scaled.shape) # -> (60000, 28, 28) : 6万枚の28x28ピクセル画像
print("学習ラベルの形状:", y_train.shape) # -> (60000,) : 各画像に対応する数字(0-9)
print("テストデータの形状:", x_test_scaled.shape) # -> (10000, 28, 28)
print("テストラベルの形状:", y_test.shape) # -> (10000,)
# モデルの構築 (Sequential APIを使用)
model = tf.keras.Sequential([
# 入力層: 28x28ピクセルの画像を784次元のベクトルに平坦化
tf.keras.layers.Flatten(input_shape = (28, 28)),
# 中間層(隠れ層): 128個のニューロンを持つ全結合層
# 活性化関数にはReLUを使用 (一般的に良い性能を発揮)
tf.keras.layers.Dense(128, activation = 'relu'),
# Dropout層: 過学習を抑制するため、20%のニューロンをランダムに無効化
# Dropoutは学習時にのみ適用され、評価・予測時には自動的に無効になる
tf.keras.layers.Dropout(0.2),
# 出力層: 10個のニューロンを持つ全結合層 (0-9の10クラス分類)
# 活性化関数にはSoftmaxを使用 (各クラスの確率を出力)
tf.keras.layers.Dense(10, activation = 'softmax')
])
# モデルの構造を確認
model.summary()
# モデルのコンパイル
model.compile(optimizer = 'adam', # オプティマイザ: Adamアルゴリズムを使用
loss = 'sparse_categorical_crossentropy', # 損失関数: 整数ラベルの多クラス分類用
metrics = ['accuracy']) # 評価指標: 正解率を監視
# モデルの学習
history = model.fit(
x_train, y_train, # 学習データと正解ラベル
batch_size = 32, # バッチサイズ
epochs = 10, # エポック数(学習データ全体を何周するか)
validation_data = (x_test, y_test) # 検証データ
)
# モデルの評価 (テストデータを使用)
print("テストデータでモデルの性能を評価します...")
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose = 2)
print(f'\nテストデータでの損失 (Loss): {test_loss}')
print(f'テストデータでの正解率 (Accuracy): {test_accuracy}')
# テストデータからいくつか選んで予測を実行
num_predict = 5
predictions = model.predict(x_test[:num_predict])
# 予測結果の表示
print(f"\n最初の{num_predict}個のテストデータに対する予測:")
for i in range(num_predict):
predicted_label = np.argmax(predictions[i]) # 最も確率の高いクラスのインデックスを取得
true_label = y_test[i]
print(f"予測: {predicted_label}, 正解: {true_label}")
# モデルの保存
model_save_path = 'mnist_model.keras'
model.save(model_save_path)データの準備
ディープラーニングは、データからパターンを学習するため、質の高いデータを適切な形式で準備する必要があります。
MNISTの読み込みは次のように行います。
# インポート
import tensorflow as tf
# MNISTデータセットの読み込み
# (x_train, y_train):学習データ(画像とラベル)
# (x_test, y_test):テストデータ(画像とラベル)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# データの正規化
x_train_scaled = x_train / 255.0
x_test_scaled = x_test / 255.0
# データ形状の確認
print("学習データの形状:", x_train_scaled.shape) # -> (60000, 28, 28) : 6万枚の28x28ピクセル画像
print("学習ラベルの形状:", y_train.shape) # -> (60000,) : 各画像に対応する数字(0-9)
print("テストデータの形状:", x_test_scaled.shape) # -> (10000, 28, 28)
print("テストラベルの形状:", y_test.shape) # -> (10000,)
出力結果 ※Google Colabで表示

ディープラーニングでは、モデルの学習に使用するデータ(学習データ)と、学習済みモデルの性能を評価するためのデータ(テストデータ)を用意する必要があります。
MNISTでは、すでに学習データとテストデータが分かれているため、そのまま使用することができます。
実際のプロジェクトでは、CSVファイルや画像ファイルからデータを読み込み、自分で学習データとテストデータに分ける処理が必要です。
データを読み込むとき、次のように行います。
# インポート
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# CSVからデータを読み込み
df = pd.read_csv('data.csv')
# 特徴量とラベルに分割
features = df.iloc[:, :-1].values
labels = df.iloc[:, -1].values
# トレーニングデータとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(
features, labels, test_size = 0.2, random_state = 42)
ここでは、scikit-learnのtrain_test_split関数を使用しています。
サンプルコードにはありませんが、読み込んだデータ自体をそのまま使用せずに、欠損値処理、カテゴリ変数のエンコーディングなどの前処理が必要です。
scikit-learnや前処理については、こちらの記事で解説しています。
⇒ 【 scikit-learnの使い方】初心者でも使える、Pythonでの機械学習を徹底解説!
モデルの構築
KerasのSequential APIを使って、基本的なニューラルネットワークモデルを構築します。
Sequentialモデルは、層(レイヤー)を順番に積み重ねていくシンプルなモデルです。
MNISTのような画像分類タスクでは、一般的に以下のような層を組み合わせます。
- 入力層(Flatten層)
- 2次元の画像データ(例: 28x28ピクセル)を1次元のベクトル(例: 784要素)に変換します。これは、後続の全結合層(Dense層)への入力形式を整えるためです。
- 中間層・全結合層(Dense層)
- ニューラルネットワークの基本的な層です。各ニューロンが前の層のすべてのニューロンと結合しています。活性化関数(例: ReLU)を伴うことが多いです。
- Dropout層
- 過学習(Overfitting)を抑制するための層です。過学習とは、モデルが学習データに過剰に適合してしまい、未知のデータに対する性能が低下してしまう現象を指します。Dropout層は、学習中にランダムに一部のニューロンの出力を0にし(ドロップアウトし)、意図的に情報の流れを妨げることで、モデルが特定のニューロンに頼りすぎるのを防ぎ、より頑健な特徴を学習するように促します。
- 出力層(Dense層)
- 最終的な予測結果を出力する層です。分類タスクの場合、クラス数と同じ数のニューロンを持ち、活性化関数(例: Softmax)を使って各クラスに属する確率を出力します。
# モデルの構築 (Sequential APIを使用)
model = tf.keras.Sequential([
# 入力層: 28x28ピクセルの画像を784次元のベクトルに平坦化
tf.keras.layers.Flatten(input_shape = (28, 28)),
# 中間層(隠れ層): 128個のニューロンを持つ全結合層
# 活性化関数にはReLUを使用 (一般的に良い性能を発揮)
tf.keras.layers.Dense(128, activation = 'relu'),
# Dropout層: 過学習を抑制するため、20%のニューロンをランダムに無効化
# Dropoutは学習時にのみ適用され、評価・予測時には自動的に無効になる
tf.keras.layers.Dropout(0.2),
# 出力層: 10個のニューロンを持つ全結合層 (0-9の10クラス分類)
# 活性化関数にはSoftmaxを使用 (各クラスの確率を出力)
tf.keras.layers.Dense(10, activation = 'softmax')
])
# モデルの構造を確認
model.summary()
出力結果 ※Google Colabで表示
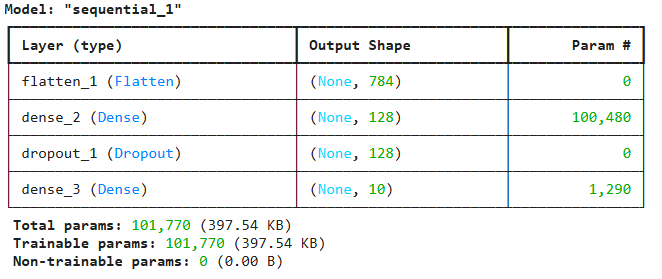
tf.keras.Sequential([…]):層をリスト形式で渡して、順番に積み重ねたモデルを作成します。
tf.keras.layers.Flatten(input_shape = (28, 28)):最初の層で入力データの形状を指定します。ここでは28x28の画像を入力とします。
tf.keras.layers.Dense(128, activation = 'relu'):128個のニューロンを持つ中間層です。activation='relu'は、活性化関数としてReLU(Rectified Linear Unit)を指定しています。ReLUは、入力が0以下の場合は0を、0より大きい場合はその値をそのまま出力する関数で、近年のディープラーニングで広く使われています。
tf.keras.layers.Dropout(0.2):0.2 という値はドロップアウト率を表し、この層の入力ユニットの20%を、学習の各ステップでランダムに0に設定します。Dropoutは学習中にのみアクティブになり、モデルの評価や予測(推論)を行う際には自動的に無効化され、全てのニューロンが使用されます。
tf.keras.layers.Dense(10, activation = 'softmax'):10個のニューロンを持つ出力層です。MNISTは0から9までの10クラス分類なので、ニューロン数は10です。activation='softmax'は、出力層でよく使われる活性化関数で、全ニューロンの出力値の合計が1になるように正規化し、各クラスに属する確率を表現します。
model.summary():モデルの各層の名前、出力形状、パラメータ数などが表示され、モデルの構造を把握するのに役立ちます。
今回はシンプルな全結合ネットワークを構築しましたが、TensorFlowでは畳み込みニューラルネットワーク(CNN)やリカレントニューラルネットワーク(RNN)など、より高度なモデルも構築可能です。
モデルのコンパイル
モデルの構造を定義したら、次は学習プロセスを設定する「コンパイル」を行います。
コンパイルでは、主に以下の3つを指定します。
- 損失関数(Loss Function)
- モデルの予測が正解からどれだけずれているかを測る指標です。モデルはこの損失を最小化するように学習を進めます。
例:sparse_categorical_crossentropy(整数ラベルの多クラス分類)、categorical_crossentropy(one-hotエンコーディングされたラベルの多クラス分類)、binary_crossentropy(二値分類)、mse(平均二乗誤差、回帰問題) - オプティマイザ(Optimizer)
- 損失関数の値を最小化するために、モデルの内部パラメータ(重み)をどのように更新するかを決定するアルゴリズムです。
例:Adam(効率的で広く使われる)、SGD(確率的勾配降下法)、RMSprop - 評価指標(Metrics)
- 学習中や評価時にモデルの性能を監視するための指標です。損失関数とは異なり、人間がモデルの性能を直感的に理解するために使われます。
例:accuracy(正解率)
# モデルのコンパイル
model.compile(optimizer = 'adam', # オプティマイザ: Adamアルゴリズムを使用
loss = 'sparse_categorical_crossentropy', # 損失関数: 整数ラベルの多クラス分類用
metrics = ['accuracy'] # 評価指標: 正解率を監視
)optimizer='adam':オプティマイザとしてAdamを指定します。Adamは多くの場合で良好な性能を発揮するため、最初の選択肢としてよく使われます。
loss='sparse_categorical_crossentropy':損失関数を指定します。MNISTのラベル(y_train, y_test)は0から9の整数値です。このような整数形式のラベルを用いた多クラス分類問題では、sparse_categorical_crossentropyを使用します。もしラベルがone-hotエンコーディングされていれば、categorical_crossentropyを使用します。
metrics=['accuracy']:学習や評価の際に、モデルの正解率(accuracy)を計算して表示するように指定します。
モデルの学習
準備したデータを使ってモデルを学習させます。
# モデルの学習
history = model.fit(
x_train, y_train, # 学習データと正解ラベル
batch_size = 32, # バッチサイズ
epochs = 10, # エポック数(学習データ全体を何周するか)
validation_data = (x_test, y_test) # 検証データ
)出力結果 ※Google Colabで表示
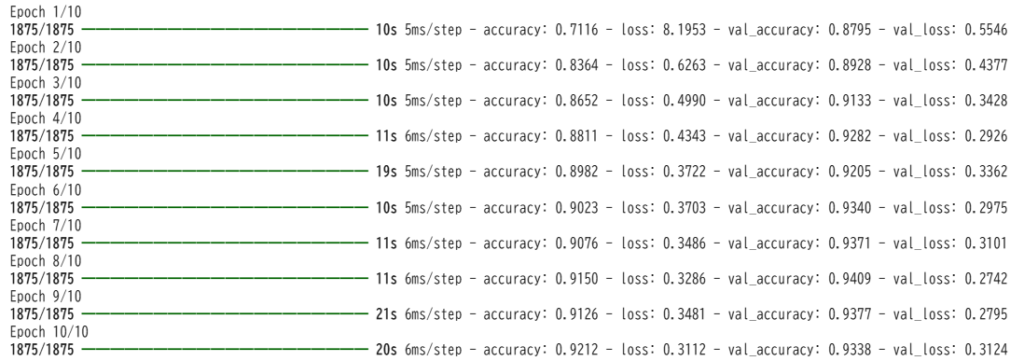
batch_size = 32:学習データを32個ずつの小さなバッチに分割し、1バッチごとにモデルのパラメータを更新します。バッチサイズはメモリ使用量や学習の安定性に影響します。
epochs = 10:データセット全体を10回繰り返して学習します。1エポックでデータ全体を一通り学習します。エポック数を増やすと学習は進みますが、増やしすぎると過学習のリスクがあるので注意が必要です。
モデルの評価
モデルの学習が完了したら、そのモデルが学習に使用していないテストデータに対してどれくらいの性能を発揮するかを評価します。
# モデルの評価 (テストデータを使用)
print("テストデータでモデルの性能を評価します...")
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose = 2)
print(f'\nテストデータでの損失 (Loss): {test_loss}')
print(f'テストデータでの正解率 (Accuracy): {test_accuracy}')出力結果 ※Google Colabで表示

model.evaluate(x_test, y_test, …):テストデータ (x_test, y_test) を使ってモデルの最終的な性能を評価します。
verbose = 2:評価の進捗表示のレベルを指定します(0:表示なし, 1:プログレスバー, 2:エポックごとに1行表示)。
戻り値:コンパイル時に指定した損失 (test_loss) とメトリクス (test_accuracy) の値が返されます。
ここで得られたテストデータでの正解率が、構築したモデルの「実力」に近い値となります
予測の実行
学習済みモデルを使って新しいデータに対して予測を行うことができます。
# インポート
import numpy as np
# テストデータからいくつか選んで予測を実行
num_predict = 5
predictions = model.predict(x_test[:num_predict])
# 予測結果の表示
print(f"\n最初の{num_predict}個のテストデータに対する予測:")
for i in range(num_predict):
predicted_label = np.argmax(predictions[i]) # 最も確率の高いクラスのインデックスを取得
true_label = y_test[i]
print(f"予測: {predicted_label}, 正解: {true_label}")出力結果 ※Google Colabで表示

model.predict(x_test[:num_predict]):テストデータの最初のnum_predict個の画像を入力として、モデルに予測させます。
predictions:model.predict()の戻り値は、各入力データに対する予測結果の配列です。今回のモデルでは、出力層の活性化関数がSoftmaxなので、各要素は10個の数値(各クラス0〜9に属する確率)を持つ配列になります。
np.argmax(predictions[i]):予測結果(確率の配列)の中で、最も値が大きい要素のインデックスを取得します。これが、モデルが最も可能性が高いと判断したクラス(数字)になります。
結果の確認:予測されたラベルと実際の正解ラベルを比較し、モデルが正しく画像を分類できているかを確認します。
モデルの保存と読み込み
学習済みモデルは保存しておくことで、再学習なしで再利用できます。
モデルの構造や学習済みのパラメータ、コンパイル時の設定(オプティマイザの状態など)を含めて保存・読み込みが可能です。
# モデルの保存
model_save_path = 'mnist_model.keras'
model.save(model_save_path)
# 保存したモデルの読み込み
loaded_model = tf.keras.models.load_model(model_save_path)
# 読み込んだモデルの構造を確認
loaded_model.summary()model.save('my_mnist_model.keras’):modelオブジェクト全体をmy_mnist_model.kerasという名前のファイルに保存します。.keras 形式以外にSavedModel形式とHDF5形式の保存方法がありますが、現在は.keras 形式が推奨されています。
tf.keras.models.load_model('my_mnist_model'): 保存されたファイルを指定して、modelオブジェクト全体を読み込みます。
TensorFlowのメリット・デメリット
TensorFlowのメリット
TensorFlowのメリットは次のとおりです。
- ユーザーが多い
- 汎用性・拡張性が高い
- 高速処理(GPU分散学習)ができる
ユーザーが多い
TensorFlowは世界中で広く使われているため、公式ドキュメントやチュートリアルなどの学習リソースが非常に豊富です。
活発なオンラインコミュニティが存在し、疑問点や問題が発生しても解決策を見つけやすい環境が整っています。
TensorFlowの実装例や事前学習済みモデルも多数あり、効率的な開発や学習が可能です。
汎用性・拡張性が高い
TensorFlowは画像認識や自然言語処理、時系列予測などの分野に対応可能です。
高水準APIのKerasを使えば標準的なモデルを簡単に構築でき、低水準APIを使えば研究レベルの複雑なモデルも自由に設計・実装できます。
TensorFlowで開発したモデルはサーバー、モバイル(TensorFlow Lite)、Web(TensorFlow.js)など多様な環境に展開できます。
高速処理(GPU分散学習)ができる
TensorFlowはNVIDIA製のGPUやGoogleが開発したTPUといった、並列計算に特化したハードウェアを最大限に活用するように設計されています。
これにより、CPUのみの場合と比較して、ディープラーニングの学習にかかる時間を大幅に短縮できます。
TensorFlowのデメリット
TensorFlowのデメリットは次のとおりです。
- 習得に時間がかかる
- エラーメッセージが分かりづらいことがある
- バージョン間の互換性に問題がある
習得に時間がかかる
TensorFlowでは、テンソルや計算グラフといった特有の概念やAPI群を理解し使いこなす必要があり、TensorFlowの学習には相応の学習時間が必要です。
特に低水準APIの利用や複雑なモデルのデバッグには、ある程度の経験と知識が求められます。
エラーメッセージが分かりづらいことがある
TensorFlowの内部的な計算グラフ構造や、テンソルの形状(Shape)の不一致に起因するエラーは、コード上の直接的な原因箇所を特定しにくい場合があります。
エラーメッセージだけでは問題解決が難しいこともあり、TensorBoardの活用やtf.printでのデバッグが必要になります。
バージョン間の互換性に問題がある
TensorFlowのバージョンアップに伴ってAPIの変更や機能の削除が行われ、過去のコードが動作しなくなることがあります。
特にTensorFlow 1.x系と2.x系では大きな違いがあり、公開されているコードを流用する場合は注意が必要です。
他の機械学習ライブラリとの比較
| ライブラリ | 特徴 | 用途 |
|---|---|---|
| TensorFlow | 柔軟なアーキテクチャ、分散処理、本番デプロイ | ディープラーニング、大規模データ、モバイルデプロイ |
| scikit-learn | 簡潔なAPI、豊富な機能、良いドキュメント | 伝統的な機械学習アルゴリズム、小〜中規模データ |
| PyTorch | 動的計算グラフ、研究向け、Pythonライク | 研究開発、ディープラーニング実験 |
| XGBoost | 勾配ブースティングに特化、高速、高精度 | 構造化データの予測タスク、コンペティション |
| LightGBM | 非常に高速、メモリ効率が良い | 大規模構造化データ、高速な学習が必要な場合 |
TensorFlowは、ディープラーニングをする時におすすめのライブラリです。
TensorFlowのテクニック
学習履歴の可視化
学習履歴を可視化することで、学習が適切に進んでいるかを確認することができます。
# インポート
import matplotlib.pyplot as plt
import tensorflow as tf
# モデルの構築
model = tf.keras.Sequential(...) # 詳細は省略
# モデルの学習
history = model.fit(...) # 詳細は省略
# Accuracy (正解率) のプロット
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.9, 1]) # Y軸の範囲を調整
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# Loss (損失) のプロット
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()出力結果 ※Google Colabで表示
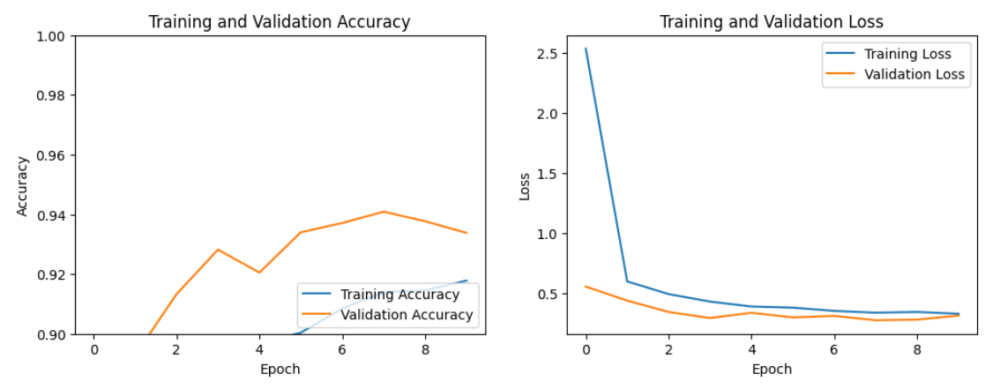
学習曲線を見ると、学習データの精度(Training Accuracy)とテストデータの精度(Validation Accuracy)が共に向上し、かつ両者の間に大きな乖離がないかを確認します。
学習データの精度が高く、テストデータの精度が頭打ちしたり低下したりする場合は、過学習の可能性があります
TensorBoardによる可視化
TensorBoardは、TensorFlowに組み込まれた可視化ツールです。
学習の進行状況や、モデルの構造、各種メトリクスなどを視覚的に確認できます。
TensorBoardを使用することで、モデルの問題点を早期に発見したり、チューニングの方向性を決めやすくなります。
# インポート
import tensorflow as tf
import datetime
# モデルの構築
model = tf.keras.Sequential(...) # 詳細は省略
# ログを保存するディレクトリを指定
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# コールバックの設定
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# モデルの学習
model.fit(x_train, y_train, epochs=10, callbacks=[tensorboard_callback])モデルの学習(model.fit())を実行すると、指定したlog_dirにログファイルが生成されます。学習中または学習後に、コマンドプロンプトを開き、以下のコマンドを実行します。
tensorboard --logdir logs/fitコマンドを実行すると、ターミナルにURL(http://localhost:6006/)が表示されるので、それをWebブラウザで開きます。
乱数シード固定による再現性の確保
モデルの学習や評価の再現性を確保するためには、乱数シードを固定することが不可欠です。
TensorFlowだけでなく、Python標準の random モジュールや、NumPyのシードも合わせて固定する必要があります。
乱数シードを固定するには、コードの冒頭で以下のように設定します。
# インポート
import tensorflow as tf
import numpy as np
import random
# 乱数シードの固定
seed_value = 42
random.seed(seed_value)
np.random.seed(seed_value)
tf.random.set_seed(seed_value)学習率スケジューリング
学習率スケジューリングとは、モデルの学習を効率的に行うために、学習率を調整する方法のことです。
学習の初期は大きめの学習率で大胆にパラメータを更新し、学習が進むにつれて学習率を小さくしていくことで、より細かく最適な解に近づけることができます。
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(
monitor = 'val_loss', # 監視する値
factor = 0.2, # 減少させる係数
patience = 5, # 何エポック改善がなければ減少させるか
min_lr = 0.0001 # 最小学習率
)
model.fit(x_train, y_train, epochs = 50, callbacks = [reduce_lr])この例では、5エポック連続で検証損失が改善しなかった場合、学習率を現在の値の20%に減少させます。
早期終了(Early Stopping)による過学習対策
過学習とは、モデルが学習データに過度に適合し、新しいデータに対する精度が低下する状態を指します。
過学習対策の1つとして、早期終了があります。
早期終了は、検証セットでの性能が改善しなくなったら学習を停止する手法です。
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor = 'val_loss', # 監視する値
patience = 10, # 何エポック改善がなければ終了するか
restore_best_weights = True # 最良の重みを復元するか
)
# モデルの学習時にコールバックとして指定
history = model.fit(
x_train, y_train,
epochs = 100, # 最大エポック数
validation_split = 0.2,
callbacks = [early_stopping]
)TensorFlowを使う際の注意点
TensorFlowのバージョン管理
TensorFlowには大きく分けて1.x系と2.x系があります。この2つは互換性が低く、書き方や仕様が大きく異なります。
- TensorFlow 1.x:セッションを使った記述が必要で、コードが複雑になりがち
- TensorFlow 2.x:Eager Execution(即時実行)がデフォルトで有効、Kerasが統合されてシンプルな記述が可能
現在は2.x系が主流です。
古いコードやチュートリアルを参照する際は、どのバージョンのTensorFlowを対象としているかを常に確認しましょう。
メモリ管理
TensorFlowはデフォルトでGPUメモリをすべて確保する場合があります。
その影響で、同じGPUで他のプロセスを動かしにくくなることがあります。
必要な分だけメモリを確保するよう設定するには、下記コードを使用します。
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
# GPUメモリの動的割り当てを設定
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)おすすめの学習方法
公式チュートリアルで学ぶ
TensorFlowの公式ドキュメントには、初心者向けから高度な内容まで多くのチュートリアルが用意されています。
Google Colabを使えば、環境構築なしでブラウザ上で直接コードを実行することも可能です。
特に「TensorFlowチュートリアル」「Kerasガイド」は、初心者におすすめです。
書籍で基礎を学ぶ
ディープラーニングとTensorFlowの基礎を体系的に学びたいなら、書籍もおすすめです。
ライブラリのバージョンに関する情報は古くなっている可能性があるので、注意しましょう。


オンラインスクールで学ぶ
TensorFlowの学習にオンラインスクールを活用することもおすすめです。
学習の中で出てきた疑問点を質問することができるため、独学での挫折を防ぎやすくなります。
おすすめのオンラインスクールはAidemy Premiumです。
TensorFlowについては、Aidemy PremiumのAI アプリ開発講座、データ分析講座、自然言語処理講座の「ディープラーニング基礎」コースで学習できます。
TensorFlowだけでなく、機械学習の基礎から応用まで幅広く学ぶことができます。
Aidemy Premiumについては、こちらの記事で解説しています。
⇒ 【徹底解説】Aidemy PREMIUMはAIを深く学ぶことができるおすすめオンラインスクール!
\最大80%給付!30秒で申し込み完了! /
Aidemy PREMIUM公式HPに飛びます
Q&A
TensorFlowとは何ですか?
TensorFlowは、Googleが開発した機械学習やディープラーニングを行うための専門的なライブラリです。
画像認識、自然言語処理、音声認識など様々な分野で使われています。
TensorFlowは何ができる?
TensorFlowでできることは次のとおりです。
- 画像認識・画像処理
- 自然言語処理
- 音声認識・音声合成
- 時系列データ分析・予測
TensorFlowとKerasの違いは?
KerasはTensorFlowの中に含まれる、TensorFlowを使いやすくするための高レベルAPIです。
難しいTensorFlowのコードをシンプルに書くことができます。
初心者は基本的に「tf.keras」から始めるのがおすすめです。
まとめ
この記事では、Pythonを使ったTensorFlowの基本的な使い方について、わかりやすく解説しました。
ディープラーニングやTensorFlowは難しく感じるかもしれませんが、基本手順を1つ1つ進めていけば、初心者でも習得できます。
まずは、この記事で紹介したMNISTのサンプルを真似してみてください。
次のステップとして、公式チュートリアルや、自分の興味のあるデータセットでモデル構築に挑戦してみるのがおすすめです。
