
- PyTorchって聞いたことあるけど、何から始めればいいの?
- ディープラーニングって難しそう……自分にできるかな?
- 手書き文字認識をAIでやってみたいけど、どうすればいいか分からない
こんな悩みを解決します。
PyTorchとは機械学習とディープラーニングのためのライブラリのことです。
PyTorchは、Pythonを使っている人には直感的に扱いやすい構造になっており、ディープラーニングの学習に適しています。
ディープラーニングを学ぶ第一歩として、PyTorchを使った手書き文字認識に取り組むのがおすすめです。
この記事では、PyTorchの使い方について、わかりやすく解説します。
この記事を読み進めれば、PyTorchの基本を理解し、実際に手書き文字認識プログラムを作成できるようになります。
PyTorchとは

PyTorchの概要
PyTorchは、Facebook(現Meta)が開発した機械学習とディープラーニングのためのライブラリです。
読み方は「パイトーチ」です。
Pythonとの親和性が高く、直感的な記述が可能なことから、研究用途から商用プロダクト開発まで幅広く利用されています。
特に、動的計算グラフ(Dynamic Computational Graph)を採用している点が大きな特徴で、柔軟でデバッグしやすいコードを書くことができます。
PyTorchの主な特徴
PyTorchの主な特徴は次のとおりです。
- 動的計算グラフ(Dynamic Computational Graph)
- Pythonicなインターフェース
- GPUによる高速な計算
- 豊富なAPIとモジュール
- エコシステム
動的計算グラフ(Dynamic Computational Graph)
PyTorchでは、動的計算グラフを採用しています。
動的計算グラフとはコードを実行しながらグラフを構築する仕組みです。
計算グラフとは、数式や処理の流れをグラフ構造で表現する考え方です。
ディープラーニングでは、ニューラルネットワークの各演算(加算、乗算、活性化関数など)をノード(点)として表し、それらの依存関係をエッジ(線)で結ぶことで、モデル全体の処理の流れを明示的に管理します。
動的計算グラフには次のメリットがあります。
- if文やfor文などPythonの構文がそのまま使える
- モデルの構造を柔軟に変更できる
- デバッグが簡単でエラー箇所を特定しやすい
Pythonicなインターフェース
PyTorchはPythonとの親和性が非常に高く、Pythonicなインターフェースを持っています。
NumPyのような書き方でテンソル操作ができるため、Pythonを使った開発に慣れている方には非常に扱いやすいライブラリです。
GPUによる高速な計算
PyTorchはCUDA対応のGPUを活用して高速にモデルを学習・推論することができます。
モデルとデータをGPUへ移動するとき、次のように簡単なコードで記述することが可能です。
# インポート
import torch
# CPUでのテンソル計算
tensor_cpu = torch.tensor([1, 2, 3])
# GPUでの高速計算に切り替え
tensor_gpu = tensor_cpu.to('cuda')豊富なAPIとモジュール
PyTorchには、ディープラーニングモデルを効率的に構築するための豊富なAPIとモジュールが組み込まれています。
主なAPI・モジュールは次のとおりです。
- torch.nn
- ニューラルネットワークの層(Linear層、Convolution層など)、活性化関数(ReLU、Sigmoidなど)、損失関数(CrossEntropyLoss、MSELossなど)といった、モデル構築に必要な基本的な部品がまとまっています。これらを組み合わせることで、様々な構造のネットワークを簡単に定義できます。
- torch.optim
- モデルのパラメータを更新するための最適化アルゴリズム(SGD、Adam、AdamWなど)が提供されています。数行のコードで、学習プロセスに最適化手法を組み込めます。
- torch.utils.data
- データセットの読み込み、前処理、バッチ処理などを効率化するためのユーティリティ(Dataset、DataLoaderなど)が含まれています。これにより、大量のデータを扱う際の定型的な処理を簡潔に記述できます。
- 自動微分
- ディープラーニングの学習に不可欠な勾配計算を自動で行う機能です。ユーザーは複雑な微分計算を意識することなく、順伝播(Forward Propagation)の計算を定義するだけで、PyTorchが自動的に逆伝播(Backward Propagation)に必要な勾配を計算してくれます。
エコシステム
PyTorchには、様々な特定分野に特化した拡張ライブラリが豊富に存在します。
これらを総称して「PyTorchエコシステム」と呼びます。
- torchvision:画像認識タスク向けのデータセット、モデルアーキテクチャ、変換処理を提供
- torchaudio:音声処理と音声認識のためのツールとデータセット
- torchtext:自然言語処理向けの前処理ツールとデータセット
- TorchRL:強化学習のための実装フレームワーク
- TensorDict:複雑なデータ構造を効率的に扱うためのツール
- TorchRec:推薦システム構築のための専用ライブラリ
- torchtune:ハイパーパラメータチューニングのためのツール
- PyTorch Hub:事前学習済みモデルの共有と再利用のためのプラットフォーム
- TorchMetrics:モデル評価のための統一的な指標計算ライブラリ
- Captum:モデルの解釈可能性を高めるためのツール
PyTorchの環境構築
ライブラリのインストール
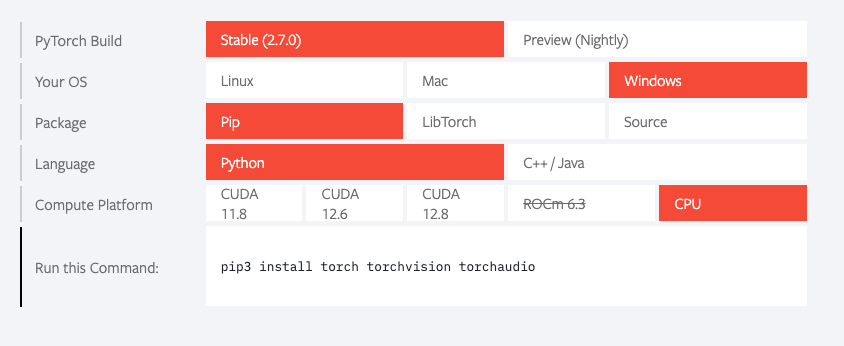
PyTorchをインストールしていない場合は、下記コマンドをコマンドプロンプトで実行しましょう。
pip3 install torch torchvision torchaudioPyTorchの公式サイトでは、自分の環境(Windows/Linux/Mac, CUDAバージョンなど)に合わせたインストールコマンドが案内されるのでおすすめです。
PyTorchを使用するときは、仮想環境の使用がおすすめです。
仮想環境を使うと、プロジェクトごとに異なるバージョンのライブラリを使用でき、環境の衝突を避けられます。
仮想環境の作成例は次の通りです。
# 仮想環境の作成(仮想環境名は変更可能)
python -m venv pytorch_env
# 仮想環境の有効化(Windows)
pytorch_env\Scripts\activate
# PyTorchのインストール
pip3 install torch torchvision torchaudio仮想環境については、こちらの記事で解説しています。
⇒ 【Python仮想環境】初心者でもできるvenvによる仮想環境作成方法を解説!
Google Colabでの使用
Google Colab(Google Colaboratory)は、ブラウザ上でPythonコードを実行できる無料の開発環境です。
Google ColabにはPyTorchがプリインストールされているので、すぐに使用できます。
Google ColabはGPUも無料で使えるため、ディープラーニングを学ぶのに最適です。
Google Colabについては、こちらの記事で解説しています。
⇒ 【Google Colabの使い方】ブラウザ上のPython開発環境を解説!Google Driveへの連携方法も紹介
ライブラリの使用方法
PyTorchを使用するときは下記のようにインポートします。
import torch個別のモジュールをインポートする場合の例を紹介します。
ニューラルネットワークモジュール
import torch.nn as nn最適化アルゴリズム
import torch.optim as optim機能的な操作
import torch.nn.functional as Fデータローダとデータセット
from torch.utils.data import DataLoader, Dataset自動微分
import torch.autograd as autograd分散処理
import torch.distributed as distビジョン関連
import torchvision
import torchvision.transforms as transforms自然言語処理
import torchtextPyTorchの基本フロー
PyTorchを使ったディープラーニングの基本的な流れは以下のとおりです。
- データの準備
- モデルの定義
- 損失関数と最適化手法の定義
- モデルの学習
- モデルの評価
- 予測の実行
- モデルの保存と読み込み
PyTorchの基本フローについて、手書き数字の画像データセットとして有名なMNISTを使い、解説します。
サンプルコード全体は次のとおり。
# インポート
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
################
## データの準備 ##
################
# 前処理の定義
transform = transforms.Compose([
transforms.ToTensor(), # 画像をPyTorchのテンソルに変換
transforms.Normalize((0.1307,), (0.3081,)) # MNISTの平均と標準偏差でデータを正規化
])
# 学習データのダウンロードと準備
train_dataset = torchvision.datasets.MNIST(
root='./data', # データの保存先
train=True, # 学習データを取得
download=True, # データがなければダウンロード
transform=transform # 前処理を適用
)
# テストデータのダウンロードと準備
test_dataset = torchvision.datasets.MNIST(
root='./data',
train=False,
download=True,
transform=transform
)
# データセットの情報を表示
print(f"学習データサイズ: {len(train_dataset)}")
print(f"テストデータサイズ: {len(test_dataset)}")
print(f"画像の形状: {train_dataset[0][0].shape}")
print(f"クラス数: {len(train_dataset.classes)}")
# データローダの作成
batch_size = 64
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True # エポックごとにデータをシャッフル
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False
)
################
## モデルの定義 ##
################
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self):
super().__init__()
# 全結合層の定義
self.fc1 = nn.Linear(28 * 28, 128) # 入力784, 中間層1ノード数128
self.fc2 = nn.Linear(128, 64) # 中間層1ノード数128, 中間層2ノード数64
self.fc3 = nn.Linear(64, 10) # 中間層2ノード数64, 出力層ノード数10
# Dropout層の定義 (pはドロップアウト率、無効化するノードの割合)
# 学習時にのみ適用され、推論時(model.eval()時)には自動的に無効になる
self.dropout = nn.Dropout(p=0.5) # 50%のノードを無効化
def forward(self, x):
# フォワード(順伝播)の計算を定義
# xの形状: [バッチサイズ, 1, 28, 28] -> [バッチサイズ, 784]に平坦化
x = x.view(-1, 28 * 28)
# 中間層1: 全結合 -> ReLU -> Dropout
x = F.relu(self.fc1(x))
x = self.dropout(x) # 学習時にのみDropoutを適用
# 中間層2: 全結合 -> ReLU -> Dropout
x = F.relu(self.fc2(x))
x = self.dropout(x) # 学習時にのみDropoutを適用
# 出力層
x = self.fc3(x)
return x
# モデルのインスタンスを作成
net = Net()
print(net)
############################
## 損失関数と最適化手法の定義 ##
############################
# 損失関数: 交差エントロピー損失
criterion = nn.CrossEntropyLoss()
# 最適化手法: Adam
optimizer = optim.Adam(net.parameters(), lr=0.001)
################
## モデルの学習 ##
################
# データセット全体を学習する回数の設定
num_epochs = 5
print('モデルの学習 開始')
for epoch in range(num_epochs): # エポック数だけループ
# モデルを学習モードに設定
net.train()
# 初期化
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# データローダーから入力データとラベルを取得
inputs, labels = data
# モデルパラメータの勾配をリセット
optimizer.zero_grad()
# 順伝播: モデルで予測を計算
outputs = net(inputs)
# 損失の計算
loss = criterion(outputs, labels)
# 逆伝播: 勾配を計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失を記録
running_loss += loss.item()
if i % 200 == 199: # 200ミニバッチごとに進捗を表示
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
print('学習終了')
################
## モデルの評価 ##
################
# モデルを評価モードに設定
net.eval()
# 初期化
correct = 0
total = 0
# 勾配計算を無効化してメモリ使用量を削減
with torch.no_grad():
for data in test_loader:
images, labels = data
# モデルで予測
outputs = net(images)
# 最もスコアの高いクラスを予測結果とする
# outputs は [バッチサイズ, 10クラスのスコア] のテンソル
# torch.max は (値, インデックス) のタプルを返す。インデックスが予測クラスに対応
_, predicted = torch.max(outputs, 1)
# 正解数をカウント
total += labels.size(0) # バッチサイズを加算
correct += (predicted == labels).sum().item() # 予測と正解が一致した数を加算
# 全テストデータに対する正解率を計算して表示
accuracy = 100 * correct / total
print(f'正解率: {accuracy:.2f} %')
##############
## 予測の実行 ##
##############
# モデルを評価モードに設定
net.eval()
# テストデータローダーから最初のバッチを取得
dataiter = iter(test_loader)
images, labels = next(dataiter)
# モデルで予測 (最初の5枚)
with torch.no_grad():
outputs = net(images[:5]) # 最初の5つの画像を予測
# 予測結果を取得
_, predicted = torch.max(outputs, 1)
################
## 結果の確認 ##
################
# 結果の表示
for idx in range(5):
fig = plt.figure(figsize=(6, 2))
# 画像の表示
img = images[idx].numpy()[0]
plt.imshow(img, cmap='gray')
plt.show()
print('予測値:', f'{test_dataset.classes[predicted[idx].item()]}')
print('正解 :', f'{labels[idx].item()}')
################
## モデルの保存 ##
################
# 保存先を指定
PATH = './mnist_net.pth'
# モデルを保存
torch.save(net.state_dict(), PATH)
print(f"モデルを保存しました : {PATH}")
データの準備
モデルの学習と評価に必要なMNISTデータセットを準備します。
MNISTデータセットはPyTorchのtorchvisionから簡単にダウンロードできます。
データの準備は次の流れで行います。
- 前処理の定義
- データダウンロード
- データローダの作成
前処理の定義
# インポート
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 前処理の定義
transform = transforms.Compose([
transforms.ToTensor(), # 画像をPyTorchのテンソルに変換
transforms.Normalize((0.1307,), (0.3081,)) # MNISTの平均と標準偏差でデータを正規化
])データセットをダウンロードするときの前処理を定義します。
transforms.ToTensor():PIL ImageやNumpy配列をPyTorchが扱えるテンソル(Tensor)形式に変換します。また、画像の各ピクセルの値を0から255の範囲から0から1.0の範囲に正規化します。
transforms.Normalize((0.1307,), (0.3081,)):テンソルの値をさらに正規化します。ここでは、平均0.1307、標準偏差0.3081で正規化しています。これはモデルの学習を安定させる効果があります。
データダウンロード
# 学習データのダウンロードと準備
train_dataset = torchvision.datasets.MNIST(
root='./data', # データの保存先
train=True, # 学習データを取得
download=True, # データがなければダウンロード
transform=transform # 前処理を適用
)
# テストデータのダウンロードと準備
test_dataset = torchvision.datasets.MNIST(
root='./data',
train=False,
download=True,
transform=transform
)
# データセットの情報を表示
print(f"学習データサイズ: {len(train_dataset)}")
print(f"テストデータサイズ: {len(test_dataset)}")
print(f"画像の形状: {train_dataset[0][0].shape}")
print(f"クラス数: {len(train_dataset.classes)}")出力結果 ※Google Colabで表示

torchvision.datasets.MNISTを使って、学習用データセットとテスト用データセットをダウンロードします。
root='./data':データセットを保存するディレクトリを指定します。
train=True / train=False:学習用かテスト用かを指定します。
download=True:データセットが指定したディレクトリにない場合にダウンロードします。
transform=transform:上で定義した前処理を適用します。
データローダの作成
# データローダの作成
batch_size = 64
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True # エポックごとにデータをシャッフル
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False
)DataLoaderは、データを指定したバッチサイズに分割したり、データの順序をシャッフルしたりすることで、データセットを効率的にモデルに供給します。
batch_size = 64:一度にモデルに与えるデータ(画像)の数。メモリ容量や学習効率を考慮して決定します。
shuffle=True:学習データをエポックごとにシャッフルします。これにより、モデルがデータの順番に依存してしまうことを防ぎ、汎化性能を高めます。テストデータはシャッフルする必要はありません。
モデルの定義
ニューラルネットワークのモデルを定義します。
PyTorchでは、nn.Moduleクラスを継承してモデルを作成します。
- 入力層
- MNIST画像のピクセル数(28x28 = 784)を受け取ります。
- 中間層(隠れ層)
- 活性化関数(ここではReLU)とDropoutを含む複数の層。画像の「特徴」を抽出する役割を担います。今回は2つの中間層(128ノード、64ノード)を設けます。
- 出力層
- 最終的に0から9の10クラスのいずれかである確率(のようなもの)を出力します。ノード数は10個です。
# インポート
import torch.nn as nn
import torch.nn.functional as F # 活性化関数など
# ニューラルネットワークモデルの定義
class Net(nn.Module):
def __init__(self):
super().__init__()
# 全結合層の定義
self.fc1 = nn.Linear(28 * 28, 128) # 入力784, 中間層1ノード数128
self.fc2 = nn.Linear(128, 64) # 中間層1ノード数128, 中間層2ノード数64
self.fc3 = nn.Linear(64, 10) # 中間層2ノード数64, 出力層ノード数10
# Dropout層の定義 (pはドロップアウト率、無効化するノードの割合)
# 学習時にのみ適用され、推論時(model.eval()時)には自動的に無効になる
self.dropout = nn.Dropout(p=0.5) # 50%のノードを無効化
def forward(self, x):
# フォワード(順伝播)の計算を定義
# xの形状: [バッチサイズ, 1, 28, 28] -> [バッチサイズ, 784]に平坦化
x = x.view(-1, 28 * 28)
# 中間層1: 全結合 -> ReLU -> Dropout
x = F.relu(self.fc1(x))
x = self.dropout(x) # 学習時にのみDropoutを適用
# 中間層2: 全結合 -> ReLU -> Dropout
x = F.relu(self.fc2(x))
x = self.dropout(x) # 学習時にのみDropoutを適用
# 出力層
x = self.fc3(x)
return x
# モデルのインスタンスを作成
net = Net()
print(net)出力結果 ※Google Colabで表示

init(self):モデルの層(nn.Linearなど)を初期化します。super().init()を最初に呼び出すのが基本です。
nn.Linear(in_features, out_features):全結合層(線形変換)を定義します。in_featuresは入力ノード数、out_featuresは出力ノード数です。
nn.Dropout(p=0.5):Dropout層を定義しています。p=0.5は、学習中に各ニューロンが50%の確率で無効化される(出力が0になる)ことを意味します。Dropout層は学習時(model.train()モード)のみ適用されます。評価時や推論時(model.eval()モード)では、Dropout層は自動的に無効になります。
forward(self, x):データがモデルをどのように流れていくか(順伝播)を定義します。
x.view(-1, 28 * 28):入力画像テンソル([バッチサイズ、チャンネル数、高さ、幅])を、全結合層に入力できるように平坦化([バッチサイズ、 784])します。-1は他の次元から自動的に計算されることを意味します。
F.relu(…):活性化関数ReLU(Rectified Linear Unit)を適用します。ReLUは、入力が0以下なら0を、0より大きければその値をそのまま出力する関数で、ディープラーニングで広く使われています。これにより、モデルは非線形な関係性を学習できるようになります。
最後のself.fc3(x):出力層の計算です。出力される値は、各クラス(0〜9)に対する「スコア」のようなものになります。この後の損失関数で確率として解釈されます。
損失関数と最適化手法の定義
モデルの学習には、損失関数と最適化手法を定義する必要があります。
- 損失関数:モデルの予測と実際の答えがどれだけ違うかを数値化します。分類問題では、交差エントロピー損失がよく使われます。
- 最適化手法:損失を最小化するようにモデルのパラメータを更新する方法です。代表的なものにSGD (確率的勾配降下法) や Adam があります。
# インポート
import torch.optim as optim # 最適化手法のモジュール
# 損失関数: 交差エントロピー損失
criterion = nn.CrossEntropyLoss()
# 最適化手法: Adam
optimizer = optim.Adam(net.parameters(), lr=0.001)net.parameters():最適化対象となるモデルの全パラメータを渡します。
lr=0.001:学習率を指定します。学習率は、パラメータを一度にどれだけ更新するかを決める重要なハイパーパラメータです。大きすぎると学習が発散し、小さすぎると学習が非常に遅くなります。
モデルの学習
学習データを用いて、モデルを学習させます。
# データセット全体を学習する回数の設定
num_epochs = 5
print('モデルの学習 開始')
for epoch in range(num_epochs): # エポック数だけループ
# モデルを学習モードに設定
net.train()
# 初期化
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# データローダーから入力データとラベルを取得
inputs, labels = data
# モデルパラメータの勾配をリセット
optimizer.zero_grad()
# 順伝播: モデルで予測を計算
outputs = net(inputs)
# 損失の計算
loss = criterion(outputs, labels)
# 逆伝播: 勾配を計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失を記録
running_loss += loss.item()
if i % 200 == 199: # 200ミニバッチごとに進捗を表示
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
print('学習終了')出力結果 ※Google Colabで表示

学習データを何回繰り返すかを示すエポック数を設定し、各バッチごとに順伝播、損失計算、逆伝播、パラメータ更新を行います。
用語解説
- 順伝播
- ニューラルネットワークに入力を与え、出力(予測値)を得るプロセスのこと。モデルの定義で指定した各層で、重みやバイアスを使って計算が行われます。
- 逆伝播
- 損失を最小化するために、重みやバイアスを更新するプロセスのこと。損失から出力層に向かって勾配を計算します。
for epoch in range(num_epochs):指定したエポック数に合わせて、データセット全体を繰り返し学習します。
net.train() :モデルを学習モードに設定します。モードの設定を忘れると、Dropout層の挙動が変わってしまうため、注意しましょう。
for i, data in enumerate(train_loader, 0):trainloaderからミニバッチ単位でデータを取り出します。
optimizer.zero_grad():前回の計算結果が残らないように、モデルパラメータの勾配をリセットします 。
outputs = net(inputs):モデルにデータを入力し、予測結果を取得します。
loss = criterion(outputs, labels):モデルの予測結果と正解ラベルを使って、損失を計算します 。
loss.backward():損失を各パラメータで微分し、勾配を計算します 。これにより、各パラメータが損失にどれだけ影響を与えているかが分かります。
optimizer.step():計算された勾配に基づいて、オプティマイザがモデルのパラメータを更新します 。損失が小さくなる方向にパラメータが調整されます。
モデルの評価
モデルの学習が完了したら、そのモデルが未知のデータに対してどれくらいの性能を発揮するかを評価します。
学習に使っていないテストデータで評価することで、モデルの性能を確認できます。
# モデルを評価モードに設定
net.eval()
# 初期化
correct = 0
total = 0
# 勾配計算を無効化してメモリ使用量を削減
with torch.no_grad():
for data in test_loader:
images, labels = data
# モデルで予測
outputs = net(images)
# 最もスコアの高いクラスを予測結果とする
# outputs は [バッチサイズ, 10クラスのスコア] のテンソル
# torch.max は (値, インデックス) のタプルを返す。インデックスが予測クラスに対応
_, predicted = torch.max(outputs, 1)
# 正解数をカウント
total += labels.size(0) # バッチサイズを加算
correct += (predicted == labels).sum().item() # 予測と正解が一致した数を加算
# 全テストデータに対する正解率を計算して表示
accuracy = 100 * correct / total
print(f'正解率: {accuracy:.2f} %')出力結果 ※Google Colabで表示
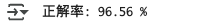
net.eval():モデルを評価モードに設定します 。モードの設定を忘れると、Dropout層の挙動が変わってしまうため、注意しましょう。
with torch.no_grad():モデル評価時は勾配計算が必要ないため、計算を無効化してメモリ使用量を削減しています。
torch.max(outputs, 1):モデルの出力から、最もスコアの高いクラスを予測結果 (predicted) とします。
予測の実行
学習したモデルを用いて、新たな手書き数字画像の予測を行います。
画像を入力し、最も確率の高いラベルを出力します。
# モデルを評価モードに設定
net.eval()
# テストデータローダーから最初のバッチを取得
dataiter = iter(test_loader)
images, labels = next(dataiter)
# モデルで予測 (最初の5枚)
with torch.no_grad():
outputs = net(images[:5]) # 最初の5つの画像を予測
# 予測結果を取得
_, predicted = torch.max(outputs, 1)
################
## 結果の確認 ##
################
# インポート
import matplotlib.pyplot as plt
# 結果の表示
for idx in range(5):
fig = plt.figure(figsize=(6, 2))
# 画像の表示
img = images[idx].numpy()[0]
plt.imshow(img, cmap='gray')
plt.show()
print('予測値:', f'{test_dataset.classes[predicted[idx].item()]}')
print('正解 :', f'{labels[idx].item()}')出力結果 ※Google Colabで表示
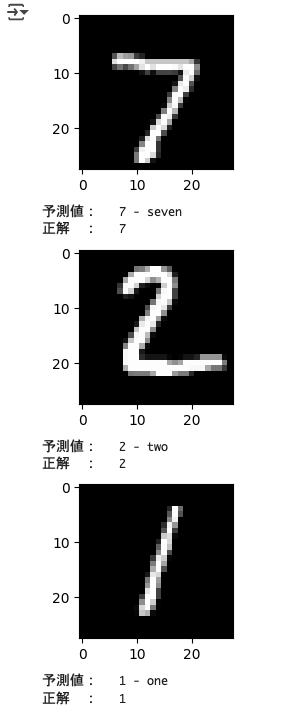
サンプルコードではテストデータの最初の5枚を使用して、画像から予測しています。
実務では、別の画像データを用意して、予測を行います。
モデルの保存と読み込み
学習済みモデルは保存しておくことで、再学習なしで再利用できます。
# 保存先を指定
PATH = './mnist_net.pth'
# モデルを保存
torch.save(net.state_dict(), PATH)
print(f"モデルを保存しました : {PATH}")
# モデルの読み込み
# 新しいモデルのインスタンスを作成 (保存時と同じクラス構造)
loaded_net = Net()
# 保存したモデルを読み込む
loaded_net.load_state_dict(torch.load(PATH))
print(f"モデルを読み込みました : {PATH}")出力結果 ※Google Colabで表示
torch.save():モデルの状態辞書 (net.state_dict()) をファイルに保存します。
保存したモデルを読み込むには、まずモデルのインスタンスを(保存時と同じ構造で)作成し、その後 load_state_dict() を使って保存した状態辞書を読み込みます。
PyTorchのメリット・デメリット
PyTorchのメリット
PyTorchのメリットは次のとおりです。
- 直感的で書きやすいコード
- 動的計算グラフ、デバッグの容易さ
- 研究開発で活用されている
直感的で書きやすいコード
PyTorchはPythonの哲学を強く反映しており、既存のPythonプログラマーにとっては非常に馴染みやすい構文となっています。
NumPyの配列操作に似たテンソル操作が可能で、デバッグもPythonの標準的なデバッガ(PDBなど)をそのまま利用できます。
動的計算グラフ、デバッグの容易さ
PyTorchの最大の特徴の一つが「動的計算グラフ」です。
これは、プログラムの実行時に計算グラフを構築していく方式で、入力データの形状が可変であったり、ループ処理の中でネットワーク構造が変化するような複雑なモデルも柔軟に記述できます。
ステップ実行しながら中間結果を確認できるため、デバッグも容易です。
研究開発で活用されている
Pythonとの親和性の高さやデバッグの容易さから、PyTorchは特に学術界や最先端の研究開発分野で広く採用されています。
PyTorchで実装されている論文が多く、そのコードがGitHubなどで公開されているため、新しい技術をいち早く試したり、自身の研究に取り入れたりすることが可能です。
PyTorchのデメリット
PyTorchのデメリットは次のとおりです。
- 本番環境への移行が複雑
- モバイル対応やエッジデバイス対応は発展途上
- APIの進化が早く互換性に注意が必要
本番環境への移行が複雑
学習済みのPyTorchモデルを製品やサービスなどの本番環境へデプロイする際には、ONNX(Open Neural Network Exchange)形式へ変換したり、C++ API (LibTorch) を利用したりするなど、一手間かかる場合がありました。
しかし、最近はTorchScriptやPyTorch Liveといった機能が強化され、Python環境がない場所やモバイルへのデプロイも以前よりスムーズに行えるようになってきています。
モバイル対応やエッジデバイス対応はTensorFlow Liteと比べると弱い
TensorFlow Liteのような軽量化フレームワークと比較すると、PyTorchのモバイルやエッジデバイスへの対応は弱いと言えます。
PyTorch MobileやPyTorch Liveの登場により、iOSやAndroidデバイス上での推論実行も可能になり、改善が進んでいます。
APIの進化が早く互換性に注意が必要
PyTorchは活発に開発が進められているため、バージョンアップに伴いAPIが変更されることがあります。
古いバージョンのコードが新しいバージョンではそのまま動かない場合もあるため、公式ドキュメントやリリースノートを注意深く確認し、必要に応じてコードを修正する必要があります。
他の機械学習ライブラリとの比較
| ライブラリ | 特徴 | 用途 |
|---|---|---|
| PyTorch | 動的計算グラフ、研究向け、Pythonライク | 研究開発、ディープラーニング実験 |
| TensorFlow | 柔軟なアーキテクチャ、分散処理、本番デプロイ | ディープラーニング、大規模データ、モバイルデプロイ |
| scikit-learn | 簡潔なAPI、豊富な機能、良いドキュメント | 伝統的な機械学習アルゴリズム、小〜中規模データ |
| XGBoost | 勾配ブースティングに特化、高速、高精度 | 構造化データの予測タスク、コンペティション |
| LightGBM | 非常に高速、メモリ効率が良い | 大規模構造化データ、高速な学習が必要な場合 |
PyTorchのテクニック
PyTorchをより効果的に使うためのテクニックを紹介します。
GPUの使用
PyTorchは、NVIDIAのCUDAに対応しており、GPUを活用することで学習速度を劇的に向上させることができます。
MNISTのサンプルコードで使用する場合は、次のように記述します。
# GPUが利用可能かチェック
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用するデバイス:{device}")
# ニューラルネットワークモデルの定義
class Net(nn.Module):
# 内容は省略
# モデルをGPUに移動
net.to(device)
# 内容は省略
for epoch in range(num_epochs): # エポック数だけループ
# モデルを学習モードに設定
net.train()
# 初期化
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# データローダーから入力データとラベルを取得
inputs, labels = data
# データをGPUに移動
inputs, labels = inputs.to(device), labels.to(device)
# 内容は省略モデルと入力データは同じデバイス上にある必要があります。片方がCPU、もう片方がGPUにあるとエラーになります。
GPUメモリには限りがあるため、バッチサイズが大きすぎたり、モデルが巨大すぎたりすると、メモリ不足 (CUDA out of memory) エラーが発生することがあります。その場合はバッチサイズを小さくするなどの調整が必要です。
GPUからCPUにテンソルを戻す場合は、.cpu() メソッドを使用します。
学習履歴の可視化
学習履歴を可視化することで、学習が適切に進んでいるかを確認することができます。
# モデルの学習
# データセット全体を学習する回数の設定
num_epochs = 5
epoch_avg_losses = []
epoch_train_accuracies = []
print('モデルの学習 開始')
for epoch in range(num_epochs): # エポック数だけループ
# モデルを学習モードに設定
net.train()
current_epoch_total_loss = 0.0 # このエポックの総損失を累積
running_loss_for_print = 0.0 # 200バッチごとの表示用損失
correct_train = 0 # このエポックの学習データでの正解数
total_train = 0 # このエポックの学習データ総数
for i, data in enumerate(train_loader, 0):
# データローダーから入力データとラベルを取得
inputs, labels = data
# モデルパラメータの勾配をリセット
optimizer.zero_grad()
# 順伝播: モデルで予測を計算
outputs = net(inputs)
# 損失の計算
loss = criterion(outputs, labels)
# 逆伝播: 勾配を計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失を記録
current_epoch_total_loss += loss.item()
running_loss_for_print += loss.item()
_, predicted = torch.max(outputs, 1)
total_train += labels.size(0)
correct_train += predicted.eq(labels).sum().item()
# 進捗表示
if i % 200 == 199:
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss_for_print / 200:.3f}')
running_loss_for_print = 0.0
# エポックごとの平均損失と正解率を計算
avg_epoch_loss = current_epoch_total_loss / len(train_loader)
epoch_accuracy = 100 * correct_train / total_train
epoch_avg_losses.append(avg_epoch_loss)
epoch_train_accuracies.append(epoch_accuracy)
print(f"Epoch [{epoch+1}/{num_epochs}], Avg Loss: {avg_epoch_loss:.4f}, Training Accuracy: {epoch_accuracy:.2f}%")
print('学習終了')
# 学習履歴の可視化
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 5))
# Accuracy (正解率) のプロット
plt.subplot(1, 2, 1)
plt.plot(epoch_train_accuracies, label='Training Accuracy', marker='o') # マーカー追加
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.ylim([min(0, min(epoch_train_accuracies)-5 if epoch_train_accuracies else 0), 100]) # Y軸下限も調整
plt.title('Training Accuracy per Epoch')
plt.grid(True)
plt.legend()
# Loss (損失) のプロット
plt.subplot(1, 2, 2)
plt.plot(epoch_avg_losses, label='Training Loss', marker='o') # マーカー追加
plt.xlabel('Epoch')
plt.ylabel('Average Loss')
# Y軸の上限を調整 (リストが空の場合も考慮)
loss_plot_ylim_upper = max(epoch_avg_losses) * 1.1 if epoch_avg_losses else 1
plt.ylim([0, loss_plot_ylim_upper])
plt.title('Average Training Loss per Epoch')
plt.grid(True)
plt.legend()
plt.tight_layout() # サブプロットのタイトルやラベルが重ならないように調整
plt.show()出力結果 ※Google Colabで表示
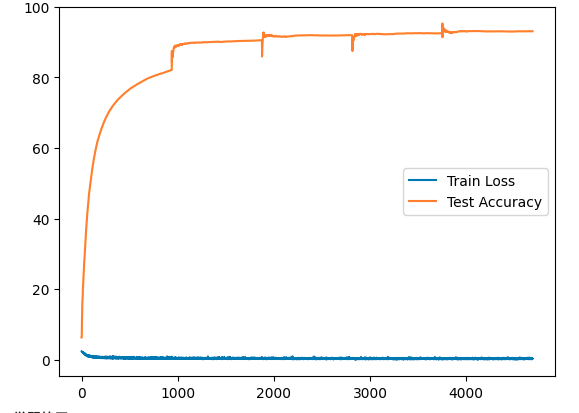
損失がエポックごとに順調に減少し、正解率が上昇していれば学習はうまくいっています。
学習データの損失は下がるのに検証データの正解率が頭打ちになったり下がり始めたりしたら、過学習の可能性があります。
TensorBoardによる可視化
より高度な可視化には、TensorBoardが便利です。
TensorBoardはTensorFlowの可視化ツールですが、PyTorchでもtorch.utils.tensorboardを使うことで、簡単に連携できます。
学習の進行状況や、モデルの構造、各種メトリクスなどを視覚的に確認できます。
TensorBoardを使用することで、モデルの問題点を早期に発見したり、チューニングの方向性を決めやすくなります。
# インポート
from torch.utils.tensorboard import SummaryWriter
# ログを保存するディレクトリを指定してSummaryWriterオブジェクトを作成
writer = SummaryWriter('runs/mnist_experiment_1')
# モデルの学習
# データセット全体を学習する回数の設定
num_epochs = 5
train_losses = []
test_accuracies = []
print('モデルの学習 開始')
for epoch in range(num_epochs): # エポック数だけループ
# モデルを学習モードに設定
net.train()
# 初期化
running_loss = 0.0
correct = 0
total = 0
for i, data in enumerate(train_loader, 0):
# データローダーから入力データとラベルを取得
inputs, labels = data
# モデルパラメータの勾配をリセット
optimizer.zero_grad()
# 順伝播: モデルで予測を計算
outputs = net(inputs)
# 損失の計算
loss = criterion(outputs, labels)
# 逆伝播: 勾配を計算
loss.backward()
# パラメータの更新
optimizer.step()
# 損失を記録
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
# エポックごとの精度を計算
accuracy = correct / total
if i % 200 == 199: # 200ミニバッチごとに進捗を表示
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')
running_loss = 0.0
# TensorBoardに記録
step = epoch * len(train_loader) + i
writer.add_scalar('training_loss', loss.item(), step)
writer.add_scalar('training_accuracy', accuracy, step)
# SummaryWriterを閉じる
writer.close()学習中または学習後に、コマンドプロンプトを開き、以下のコマンドを実行します。
tensorboard --logdir=runsコマンドを実行すると、ターミナルにURL(http://localhost:6006/)が表示されるので、それをWebブラウザで開きます。
乱数シード固定による再現性の確保
モデルの学習や評価の再現性を確保するためには、乱数シードを固定することが不可欠です。
PyTorchだけでなく、Python標準のrandom モジュールや、NumPyのシードも合わせて固定する必要があります。
乱数シードを固定するには、コードの冒頭で以下のように設定します。
# インポート
import torch
import numpy as np
import random
# 乱数シードの固定
seed_value = 42
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False学習率スケジューリング
学習率スケジューリングとは、モデルの学習を効率的に行うために、学習率を調整する方法のことです。
学習の初期は大きめの学習率で大胆にパラメータを更新し、学習が進むにつれて学習率を小さくしていくことで、より細かく最適な解に近づけることができます。
# インポート
from torch.optim.lr_scheduler import ReduceLROnPlateau
# オプティマイザの作成
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 学習率スケジューラの作成(検証損失が改善しない場合に学習率を下げる)
scheduler = ReduceLROnPlateau(optimizer, 'min', patience=3, factor=0.5, verbose=True)
# データセット全体を学習する回数の設定
num_epochs = 10
# 学習ループ内で使用
for epoch in range(num_epochs):
# 学習の詳細は省略
# スケジューラの更新
avg_val_loss = val_loss_sum / len(val_loader)
scheduler.step(avg_val_loss) # 検証セットの平均損失を渡すこの例では、ReduceLROnPlateauを使用しています。
ReduceLROnPlateau:検証セットの損失や精度の改善が停滞した場合に学習率を減衰させます。検証損失が3エポック連続で改善しない場合、学習率を0.5倍しています。
PyTorchでは、ReduceLROnPlateau以外に様々なスケジューラが用意されていますので、簡単に紹介します。
StepLR:数エポックごとに学習率を一定の割合で減衰させます。下記の例では、30エポック毎に学習率を0.5倍にしています。
# インポート
from torch.optim.lr_scheduler import StepLR
# 学習率スケジューラの作成
scheduler = StepLR(optimizer, step_size=30, gamma=0.5) MultiStepLR:指定されたエポックで学習率を減衰させます。下記の例では、30、 80エポック目で学習率を0.5倍にしています。
# インポート
from torch.optim.lr_scheduler import MultiStepLR
# 学習率スケジューラの作成
scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.5) CosineAnnealingLR:学習率をコサインカーブに従って徐々に変化させます。下記の例では、10エポックを1サイクルとして、学習率を変化させています。
# インポート
from torch.optim.lr_scheduler import CosineAnnealingLR
# 学習率スケジューラの作成
scheduler = CosineAnnealingLR(optimizer, T_max=10) PyTorchを使う際の注意点
モデルパラメータの勾配リセット
PyTorchでは、勾配は.backward()を呼び出すたびに累積されます。
勾配が累積されると、学習が不安定になるため、モデルのパラメータを更新する際に、前回の勾配をリセットする必要があります。
勾配リセットのコマンドは次のとおり。
# モデルパラメータの勾配をリセット
optimizer.zero_grad() このコードはループの先頭に記述します。
学習モードと評価モードの切り替え
ニューラルネットワークの中には、学習時と評価・予測時で挙動を変える必要がある層が存在します。代表的なものは、Dropout層とBatch Normalization層です。
PyTorchでは、これらの挙動を切り替えるため、学習モードと評価モードを切り替えます。
モードが間違った状態でDropout層を使用すると、評価時にもランダムにニューロンが無効化されてしまい、モデルの性能が不安定になったり、本来の性能よりも低く評価されたりするので、注意が必要です。
モードの切替は次のコードを使用します。
# モデルを学習モードに設定
model.train() # modelには、事前に定義したニューラルネットワークモデルを入れる# モデルを評価モードに設定
model.eval() # modelには、事前に定義したニューラルネットワークモデルを入れる学習や評価、予測を開始する直前に、対応したコードを記述します。
モデル評価や予測での勾配計算
PyTorchではモデルの学習時に、損失に対する勾配を計算しています。
学習が完了したモデルを使って評価や予測する時は、勾配の計算が必要ありません。
勾配計算を無効化することで、メモリの節約と計算の高速化が図れます。
勾配計算を無効化するときは、次のコードを使用します。
# 勾配計算を無効化してメモリ使用量を削減
with torch.no_grad():
# 評価や予測コードこのコードを使うと、評価・予測時のメモリ使用量が大幅に削減され、処理速度も向上します。
おすすめの学習方法
公式チュートリアルで学ぶ
PyTorchの公式サイトには、初心者向けから高度な内容まで多くのチュートリアルが用意されています。
英語で書かれていますが、ブラウザの翻訳機能を使用すれば、学習することができます。
Google Colabを使えば、環境構築なしでブラウザ上で直接コードを実行することも可能です。
英語に抵抗がある場合は、公式チュートリアルを日本語訳したサイトを活用しましょう。
書籍で基礎を学ぶ
ディープラーニングとPyTorchの基礎を体系的に学びたいなら、書籍もおすすめです。
ただし、ライブラリのバージョンに関する情報は古くなっている可能性があるので、注意しましょう。



オンラインスクールで学ぶ
PyTorchの学習にオンラインスクールを活用することもおすすめです。
学習の中で出てきた疑問点を質問することができるため、独学での挫折を防ぎやすくなります。
PyTorchを学習するためのおすすめスクールはキカガクです。
キカガクのオンライン講座は、動画で視覚的に学べるのが特長です。
長期コースでは機械学習・ディープラーニング・データ分析まで広くカバーされており、PyTorchを使った演習も含まれています。
学習ステップが丁寧で、未経験者でもつまずきにくい構成です。
キカガクについては、こちらの記事で解説しています。
⇒ 【徹底解説】キカガク長期コースはdodaと提携した転職おすすめのオンラインスクール!
\ 最大80%給付!30秒で申し込み/
キカガク公式HPに飛びます
Q&A
PyTorchとは何ですか?
PyTorchは、Facebook(現Meta)が開発した機械学習とディープラーニングのためのライブラリです。
Pythonとの親和性が高く、直感的な記述が可能なことから、研究用途から商用プロダクト開発まで幅広く利用されています。
PyTorchは何ができますか?
PyTorchでできることは次のとおりです。
- 画像認識・画像処理
- 自然言語処理
- 音声認識・音声合成
- 時系列データ分析・予測
テンソルとは何ですか?
テンソルは、PyTorchの基本的なデータ構造で、NumPyの多次元配列 (ndarray) に似た多次元配列です。。GPUでの計算を簡単に行うことができます。
テンソルは、テンソルに対する計算の勾配(微分値)を自動で追跡・計算する機能を持っています。この自動微分機能がディープラーニングの学習に不可欠です。
まとめ
この記事では、PyTorchの使い方について、わかりやすく解説しました。
ディープラーニングやPyTorchは難しく感じるかもしれませんが、基本手順を1つ1つ進めていけば、初心者でも習得できます。
まずは、この記事で紹介したMNISTのサンプルを真似してみてください。
次のステップとして、公式チュートリアルや、自分の興味のあるデータセットでモデル構築に挑戦してみるのがおすすめです。
