
- 効率的にデータを解析したい。
- Excelだとデータをすべて読むことができない。
- pandasって聞いたことあるけど、どんなことができるの?
こんな悩みを解決します!!
みなさん、pandasを活用していますか?
pandasはデータ解析を効率的に行うことができるライブラリです。
データをシリーズ(Series)やデータフレーム(DataFrame)という形式で処理します。
Excelではデータ量に制約がありますが、pandasでは大量のデータを扱うことが可能です。
本記事では、pandasの基本的な使い方をサンプルコードを紹介しながら、わかりやすく解説します。
よく使用するpandasのコマンドを一覧にしていますので、チートシートとして使用できます。
pandasの使い方を忘れたときに活用できますので、最後まで読んでいただけると嬉しいです!!
そもそも、pandasって何?
pandasのおさらいです。
pandasは、Pythonでデータ解析を効率的に行うことができるライブラリです。
読み方は「パンダス」です。
データをシリーズ(Series)やデータフレーム(DataFrame)という形式で処理します。
シリーズ(Series)の特徴は次のとおり。
- リストのような1次元配列
- 各値にラベルがつけられている。このラベルのことを「index」という
- データフレームの構成要素
データフレーム(DataFrame)の特徴は次のとおり。
- 2次元配列
- 行と列にラベルがつけられている。行ラベルを「index」、列ラベルを「columns」という。
データフレーム(DataFrame)は大量のデータを操作しやすい形式になっているため、データ分析や機械学習で必須のライブラリになります。
pandas 公式サイト(英語サイト)
pandasのデータフレームはJupyterLabやGoogle Colaboratory(以下Google Colab)で確認すると、枠付きの表で見ることができるの便利です。
JupyterLabについては、こちらの記事で解説しています。
⇒【JupyterLabの使い方】初心者は迷ったらこれだけ読め!
Google Colabの使い方については、こちらの記事で解説しています。
⇒【Google Colabの使い方】Pythonを手軽に始められる開発環境を解説!
ライブラリのインストール
pandasをインストールしていない方は下記コマンドをコマンドプロンプトで実行しましょう。
pip install pandasライブラリの使用方法
pandasを使用するときは下記のようにインポートしましょう。
pandasは「pd」という別名でインポートします。
import pandas as pdシリーズ、データフレームの作成
シリーズの作成 : Series()
pd.Series()でシリーズを作成できます。
引数はリスト形式、または、辞書形式の2種類で入れることができます。
# シリーズの作成
# リストでの作成
ser_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
# 辞書での作成
ser_2 = pd.Series({"キャベツ":100, "ピーマン":80, "ナス":100, "かぼちゃ":120})
# 結果
# ※ ser_1、ser_2は同じ結果になります。
# キャベツ 100
# ピーマン 80
# ナス 100
# かぼちゃ 120
# dtype: int64インデックスを指定しない場合は、番号が自動的に付加されます。
ser_3 = pd.Series([100, 80, 100, 120])
# 結果
# 0 100
# 1 80
# 2 100
# 3 120
# dtype: int64データフレームの作成 : DataFrame()
pd.DataFrame()でデータフレームを作成できます。
引数はリスト形式、または、辞書形式の2種類で入れることができます。
シリーズを使用して作成する場合は、以下のようになります。
リスト形式と辞書形式では、行と列が逆になるので注意が必要です。
行と列を入れ替えたい場合は、データフレームを転置させます。「データフレームの転置 : T、transpose()」の項目を参照してください。
# データフレームの作成
# 元データ
ser_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
ser_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
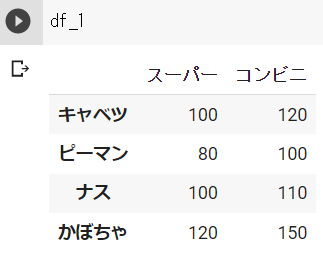
# リストでの作成
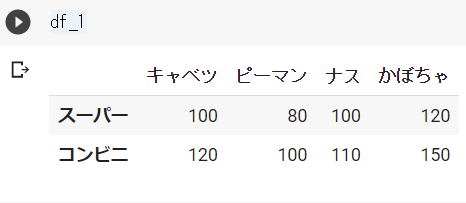
df_1 = pd.DataFrame([ser_1, ser_2], index=["スーパー", "コンビニ"])
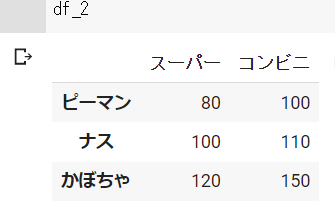
# 辞書での作成
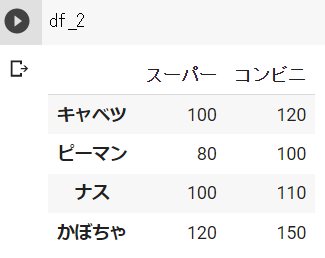
df_2 = pd.DataFrame({"スーパー":ser_1, "コンビニ":ser_2})df_1の結果 ※Google Colabで表示

df_2の結果 ※Google Colabで表示
インデックスを指定しない場合は、番号が自動的に付加されます。
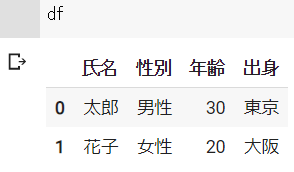
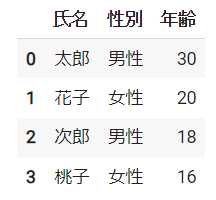
df = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})結果 ※Google Colabで表示
データフレームの表示 : head()、tail()
head()、tail()で、データフレームの先頭、最後のみを表示することができます。
データ量が多いデータフレームを表示すると、表示する行が多く見づらくなります。
head()、tail()を使用することで、データフレームの一部を表示して、内容を確認することができます。
引数には、表示したい行数を入れます。
# データフレームの表示
df = pd.DataFrame({"A": range(1,11), "B": range(11,21), "C": range(21,31)})
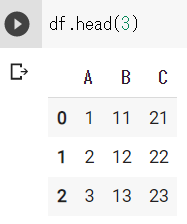
df
df.head(3)
df.tail(3)dfの結果 ※Google Colabで表示

df.head(3)、df.tail(3)の結果 ※Google Colabで表示

データフレームの情報確認 : info()
info()で、データフレームの情報を表示することができます
columnsのラベルを調べたり、データの欠損を調べたりするときに便利です。
# データフレームの情報確認
df = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})
df.info()
# 結果
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 2 entries, 0 to 1
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 氏名 2 non-null object
# 1 性別 2 non-null object
# 2 年齢 2 non-null int64
# 3 出身 2 non-null object
# dtypes: int64(1), object(3)
# memory usage: 192.0+ bytes行ラベルの取得 : index
indexで、データフレームの行ラベルを取得できます。
# 行のラベル取得1
ser_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
ser_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
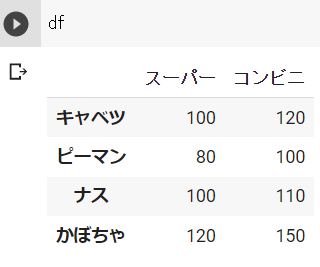
df = pd.DataFrame({"スーパー":ser_1, "コンビニ":ser_2})
df.index
# 結果
# Index(['キャベツ', 'ピーマン', 'ナス', 'かぼちゃ'], dtype='object')dfの中身 ※Google Colabで表示
行ラベルが数字の連番の場合は下記のように表示されます。
# 行ラベルの取得2
df = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})
df.index
# 結果
# RangeIndex(start=0, stop=2, step=1)dfの中身 ※Google Colabで表示
列ラベルの取得 : columns
columnsで、データフレームの列ラベルを取得できます。
# 列ラベルの取得
df = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})
df.columns
# 結果
# Index(['氏名', '性別', '年齢', '出身'], dtype='object')dfの中身は「行ラベルの取得 : index」の画像を参照してください。
データフレームの型の確認 : dtypes
dtypesで、データフレームの行ラベルのタイプを確認できます。
# データフレームの型の確認
df = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})
df.dtypes
# 結果
# 氏名 object
# 性別 object
# 年齢 int64
# 出身 object
# dtype: objectデータフレームの行数、列数の取得 : shape
shapeで、データフレームの行数、列数を取得できます。
# データフレームの行数、列数の取得
df = pd.DataFrame({"A": range(1,11), "B": range(11,21), "C": range(21,31)})
df.shape
# 結果
# (10, 3)データフレームの行数取得 : len()
len()で、データフレームの行数を取得できます。
# データフレームの行数取得
df = pd.DataFrame({"A": range(1,11), "B": range(11,21), "C": range(21,31)})
len(df)
# 結果
# 10シリーズ、データフレームの操作
データフレームの複製 : copy()
copy()で、データフレームを複製することができます。
ちなみに、「df_2 = df_1」と記入した場合、「df_2」内の値を変更すると「df_1」内の値も変更されてしまうので、注意が必要です。
# データフレームの複製
df_1 = pd.DataFrame({"氏名":["太郎", "花子"], "性別":["男性", "女性"], "年齢":[30, 20], "出身":["東京", "大阪"]})
df_2 = df_1.copy()データフレームの転置 : T、 transpose()
T、または、transpose()で、データフレームを転置させることができます。
データフレーム作成時、index(行)とcolumns(列)が逆になっている場合に修正できます。
# データフレームの転置
# 元データ
ser_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
ser_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df_1 = pd.DataFrame([ser_1, ser_2], index=["スーパー", "コンビニ"])
df_2 = df_1.T
df_3 = df_1.transpose()
転置前のデータフレーム ※Google Colabで表示
転置後のデータフレーム(df_2とdf_3は同じになります) ※Google Colabで表示

データフレーム各列の統計量 : describe()
describe()で、各列の平均や最小値、最大値といった統計量を確認できます。
# データフレーム各列の統計量
df = pd.DataFrame({"A": range(1,11), "B": range(11,21), "C": range(21,31)})
df.describe()dfの結果 ※Google Colabで表示
df.describe()の結果 ※Google Colabで表示

行ラベル、列ラベルによるデータの抽出 : loc()
loc()で、行ラベル、列ラベルを指定してデータフレームのデータを抽出することができます。
# 行番号、列番号によるデータの抽出
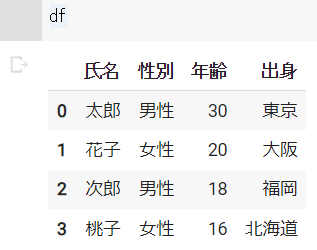
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子"], "性別":["男性", "女性", "男性", "女性"], "年齢":[30, 20, 18, 16], "出身":["東京", "大阪", "福岡", "北海道"]})
# loc[行ラベル, 列ラベル]
df.loc[0,"氏名"]
# 結果
# 30抽出結果 ※Google Colabで表示
下記のように、複数データを抽出することもできます。
df.loc[[0,2], ["性別", "出身"]]
df.loc[0:2, "性別":"出身"]抽出結果 ※Google Colabで表示


行や列をすべて抽出するときは、下記のように記入します。
df.loc[0:2, :]
df.loc[:, "性別":"出身"]抽出結果 ※Google Colabで表示


行番号、列番号によるデータの抽出 : iloc()
iloc()で、行番号、列番号を指定してデータフレームのデータを抽出することができます。
# 行番号、列番号によるデータの抽出
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子"], "性別":["男性", "女性", "男性", "女性"], "年齢":[30, 20, 18, 16], "出身":["東京", "大阪", "福岡", "北海道"]})
# iloc[行番号, 列番号]
df.iloc[0,2]
# 結果
# 30dfの結果 ※Google Colabで表示
下記のように、複数データを抽出することもできます。
df.iloc[[0,2], [1, 3]]
df.iloc[0:3, 1:4]抽出結果 ※Google Colabで表示


行や列をすべて抽出するときは、下記のように記入します。
df.iloc[0:3, :]
df.iloc[:, 1:4]抽出結果 ※Google Colabで表示


条件付による行の抽出
論理式を使用することで、条件による行の抽出を行うことができます。
# 条件付による行の抽出
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子"], "性別":["男性", "女性", "男性", "女性"], "年齢":[30, 20, 18, 16], "出身":["東京", "大阪", "福岡", "北海道"]})
#年齢が20未満の行を抽出
df[df["年齢"] < 20]結果 ※Google Colabで表示

いろいろ活用できるテクニックなので、細かく解説します。
df["列ラベル"]で、列をシリーズとして取得することができます。
ser = df["年齢"]
# 結果
# 0 30
# 1 20
# 2 18
# 3 16
# Name: 年齢, dtype: int64取得したシリーズを論理式で記入すると、各行に対する結果「True」「False」が格納されたシリーズを取得することができます。
このシリーズをdf[df["年齢"] < 20]と記入すると、「True」の行だけ抽出することができます。
ser = df["年齢"] < 20
# 結果
# 0 False
# 1 False
# 2 True
# 3 True
# Name: 年齢, dtype: bool行の追加① loc
行の追加方法は複数あるので、今回は2つ紹介します。
locの引数に新しいインデックス名を入れて、値を代入することで、行を追加することができます。
下記のように記入すると、追加した行の値がすべて同じ値が代入されます。
# 行の追加
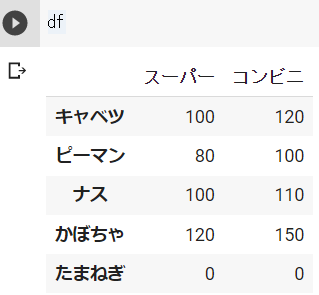
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df.loc["たまねぎ"] = 0結果 ※Google Colabで表示
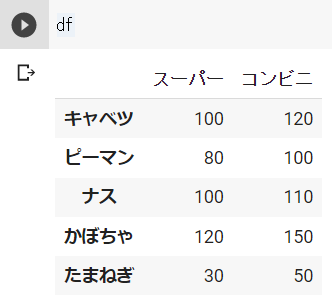
下記のようにリストを代入することで、追加した行の各値を個別に入力することができます。
# 行の追加
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df.loc["たまねぎ"] = [30, 50]結果 ※Google Colabで表示
行の追加② : append()
append()を使用することでも、行を追加することができます。
# 行の追加
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
s_3 = pd.Series([30, 50], index=["スーパー", "コンビニ"], name="たまねぎ")
df_2 = df_1.append(s_3)結果 ※Google Colabで表示
列の追加
データフレームに新しいインデックス名を入れて、値を代入することで、列を追加することができます。
下記のように記入すると、追加した列の値がすべて同じ値が代入されます。
# 列の追加
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
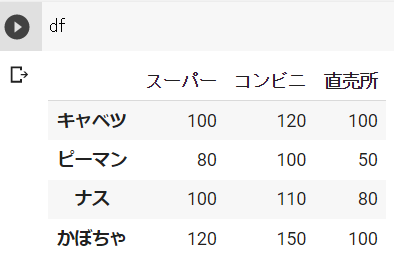
df["直売所"] = 1結果 ※Google Colabで表示

下記のようにリストを代入することで、追加した列の各値を個別に入力することができます。
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df["直売所"] = [100, 50, 80, 100]結果 ※Google Colabで表示
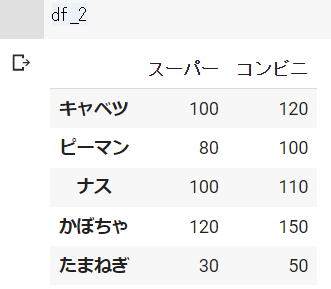
行、列の削除 : drop()
drop()で、データフレームの行や列を削除することができます。
行を削除する場合の引数は「"行ラベル"」です。
# 行の削除
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df_1 = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df_1.drop("キャベツ")df_1の結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
列を削除する場合の引数は「columns="列ラベル"」または「"列ラベル"", axis=1」です。
# 列の削除
df_1 = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子"], "性別":["男性", "女性", "男性", "女性"], "年齢":[30, 20, 18, 16], "出身":["東京", "大阪", "福岡", "北海道"]})
df_2 = df_1.drop(columns="出身")
df_3 = df_1.drop("出身", axis=1)dfの結果 ※Google Colabで表示
df_2、df_3の結果 ※Google Colabで表示
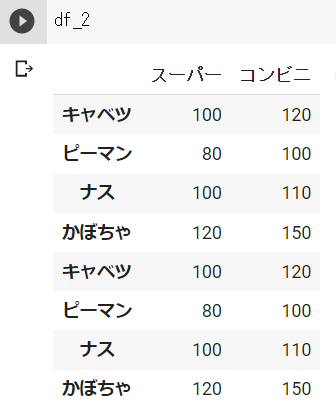
データフレームの結合 : concat()
concat()を使用することで、データフレーム同士の結合を行うことができます。
# データフレームの結合
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 110, 150], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
df_1 = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = pd.concat([df_1, df_1])df_1の結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
引数に「axis=1」と記入することで、列の追加ができます。
s_3 = pd.Series([100, 50, 80, 100], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"], name="直売所")
df_3 = pd.concat([df, s_3], axis=1)df_3の結果 ※Google Colabで表示

データフレームの情報処理
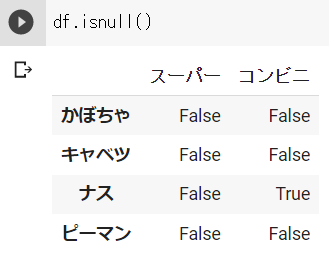
データ欠損の確認 : isnull()
isnull()を使用することで、データフレーム内で欠損(データがないこと)を調べることができます。
欠損値:True、データがある:Falseが格納されたデータフレームが返ってきます。
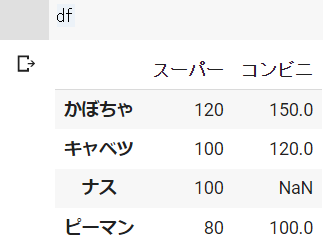
# データ欠損の確認
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.isnull()dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
df.isnull().sum()と記入すると、各列の欠損値の数を確認できます。
# 各列の欠損値の数
df.isnull().sum()
# 結果
# スーパー 0
# コンビニ 1
# dtype: int64df.isnull().any()と記入することで、欠損がある列を確認することができます。
この場合、欠損値の数はわかりません。
# 欠損がある列の確認
df.isnull().any()
# 結果
# スーパー False
# コンビニ True
# dtype: booldf.isnull().any((axis=1))と記入することで、欠損がある行を確認することができます。
# 欠損がある行の確認
df.isnull().any(axis=1)
# 結果
# かぼちゃ False
# キャベツ False
# ナス True
# ピーマン False
# dtype: bool出力された結果を利用することで、データフレームの欠損値がある行を抜き出すことも可能です。
df_3 = df[df.isnull().any(axis=1)]df_3の結果 ※Google Colabで表示

欠損行、欠損列の削除 : dropna()
dropna()を使用することで、欠損値がある行、列を削除することができます。
# 欠損行の削除
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.dropna()dfの結果 ※Google Colabで表示

df_2の結果 ※Google Colabで表示

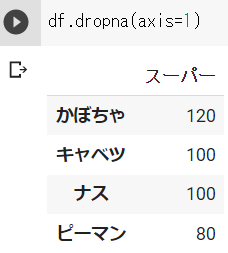
df.dropna(axis=1)と記入することで、欠損がある列を削除することができます。
# 欠損列の削除
df_3 = df.dropna(axis=1)df_3の結果 ※Google Colabで表示
直前の値で、欠損を埋める : ffill()
ffill()を使用することで、上の行の値を欠損値に代入することができます。
# 直前の値で、欠損を埋める
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.ffill()dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示

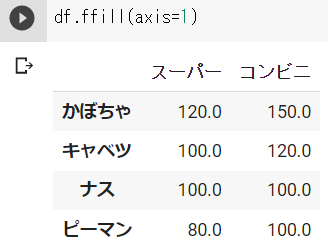
df.ffill(axis=1)と記入することで、左の列の値を欠損値に代入することができます。
df_3 = df.ffill(axis=1)df_3の結果 ※Google Colabで表示
直後の値で、欠損を埋める : bfill()
bfill()を使用することで、下の行の値を欠損値に代入することができます。
# 直後の値で、欠損を埋める
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.bfill()dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示

df.bfill(axis=1)と記入することで、右の列の値を欠損値に代入することができます。
df_3 = df.bfill(axis=1)前後の値から、欠損値を線形補完する : interpolate()
interpolate()を使用することで、前後の値から線形補完することができます。
ただし、一番上の欠損値は欠損値のままになり、一番下の欠損値は1つ上の欠損値と同じ値になります。
# 前後の値から、欠損値を線形補完する
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.interpolate()dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
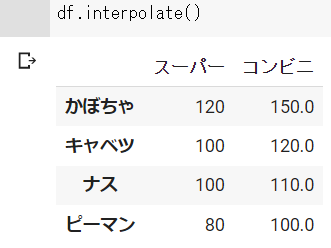
df.interpolate(axis=1)と記入することで、左右の値から線形補完することができます。
ただし、一番左の欠損値は欠損値のままになり、一番右の欠損値は1つ左の欠損値と同じ値になります。
df_3 = df.interpolate(axis=1)任意の値を欠損値に代入する : fillna()
fillna()を使用することで、任意の値を欠損値に代入することができます。
# 任意の値を欠損値に代入する
s_1 = pd.Series([100, 80, 100, 120], index=["キャベツ", "ピーマン", "ナス", "かぼちゃ"])
s_2 = pd.Series([120, 100, 150], index=["キャベツ", "ピーマン", "かぼちゃ"])
df = pd.DataFrame({"スーパー":s_1, "コンビニ":s_2})
df_2 = df.fillna(500)dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示

データが重複している行の確認 : duplicated()
duplicated()を使用することで、データが重複している行を確認することができます。
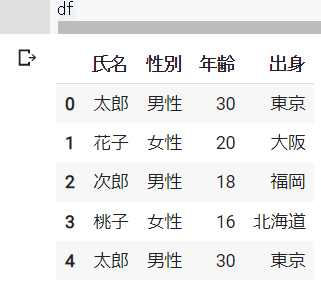
# 重複している行の確認
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子", "太郎"],
"性別":["男性", "女性", "男性", "女性", "男性"],
"年齢":[30, 20, 18, 16, 30],
"出身":["東京", "大阪", "福岡", "北海道", "東京"]})dfの結果 ※Google Colabで表示
df.duplicated()と記入すると、すべてのデータが一致する場合にTrueになります。
重複する行がない場合はFalseになります。
df.duplicated()
# 結果
# 0 False
# 1 False
# 2 False
# 3 False
# 4 True
# dtype: bool下記のように列を指定して、重複を確認することもできます。
df["性別"].duplicated()
# 結果
# 0 False
# 1 False
# 2 True
# 3 True
# 4 True
# Name: 性別, dtype: boolデータが重複している行の削除 : drop_duplicates()
drop_duplicates()を使用することで、データが重複している行を削除することができます。
# 重複している行の削除
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子", "太郎"],
"性別":["男性", "女性", "男性", "女性", "男性"],
"年齢":[30, 20, 18, 16, 30],
"出身":["東京", "大阪", "福岡", "北海道", "東京"]})
df_2 = df.drop_duplicates()dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
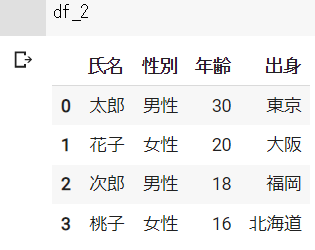
下記のように列を指定して、重複を削除することもできます。
df_3 = df.drop_duplicates("性別")df_3の結果 ※Google Colabで表示
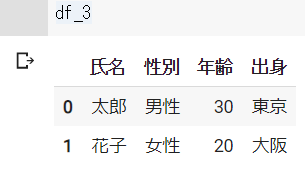
データのソート : sort_values()
sort_values()を使用することで、データをソートすることができます。
特に指定しないと昇順でソートされます。
# データのソート
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子", "太郎"],
"性別":["男性", "女性", "男性", "女性", "男性"],
"年齢":[30, 20, 18, 16, 30],
"出身":["東京", "大阪", "福岡", "北海道", "東京"]})
# 昇順
df_2 = df.sort_values("年齢")dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
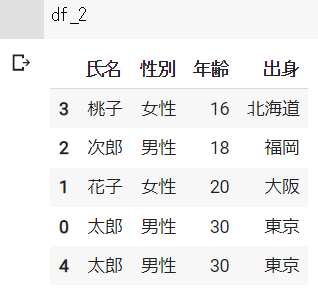
引数に「ascending=False」と入力することで、降順でソートできます。
# 降順
df_3 = df.sort_values("年齢", ascending=False)df_3の結果 ※Google Colabで表示
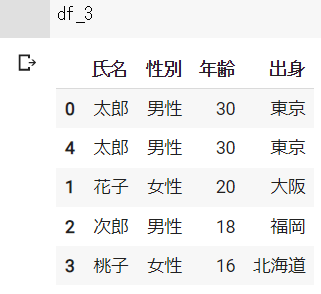
インデックスの初期化 : reset_index()
reset_index()を使用することで、インデックスを初期化することができます。
行の削除やソートにより、実際の並びと整合が取れなくなったインデックスを修正することができます。
# インデックスの初期化
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子", "太郎"],
"性別":["男性", "女性", "男性", "女性", "男性"],
"年齢":[30, 20, 18, 16, 30],
"出身":["東京", "大阪", "福岡", "北海道", "東京"]})
# 昇順にソート
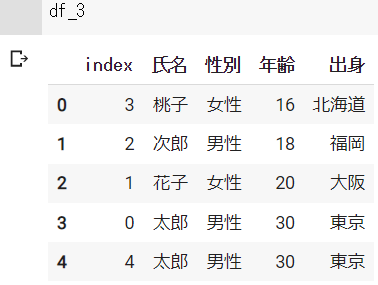
df_2 = df.sort_values("年齢")
df_3 = df_2.reset_index()df_2の結果 ※Google Colabで表示
df_3の結果 ※Google Colabで表示
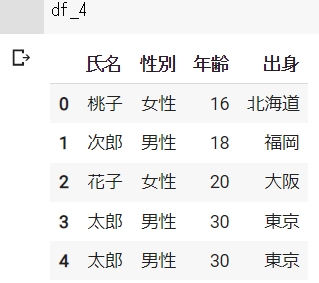
初期化前のインデックスを残したくない場合、引数に「drop=True」を入れます。
df_4 = df_2.reset_index(drop=True)df_4の結果 ※Google Colabで表示
データの集計
データの合計や最大値、最小値、平均を求めることができます。
# データフレーム各列の統計量
df = pd.DataFrame({"A": range(1,6), "B": range(11,16), "C": range(21,26)})dfの結果 ※Google Colabで表示

# 合計
b_1 = df.sum()
# A 15
# B 65
# C 115
# dtype: int64
# 最大値
b_2 = df.max()
# A 5
# B 15
# C 25
# dtype: int64
# 最小値
b_3 = df.min()
# A 1
# B 11
# C 21
# dtype: int64
# 平均値
b_4 = df.mean()
# A 3.0
# B 13.0
# C 23.0
# dtype: float64グループ化して集計 : groupby()
groupby()を使用することで、特定のグループを作成して、データを集計することができます。
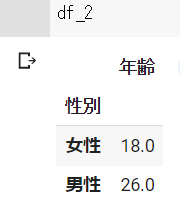
下記の例では、性別のグループに分けて、年齢の平均を出しています。
# グループ化して集計
df = pd.DataFrame({"氏名":["太郎", "花子", "次郎", "桃子", "太郎"],
"性別":["男性", "女性", "男性", "女性", "男性"],
"年齢":[30, 20, 18, 16, 30],
"出身":["東京", "大阪", "福岡", "北海道", "東京"]})
df_2 = df.groupby("性別").mean("年齢")dfの結果 ※Google Colabで表示
df_2の結果 ※Google Colabで表示
ピボット : pivot()
pivot()を使用することで、データを再構成することができます。
引数は「index」「columns」「values」の3つです。
- index : 新しいデータフレームの行インデックスになる列名
- columns : 新しいデータフレームの列名になる値を含む列名
- values : 新しいデータフレームのデータとして使用される値を含む列名
# サンプルデータフレームの作成
data = {
'日付': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'都市': ['東京', '大阪', '東京', '大阪'],
'温度': [10, 12, 11, 13],
'降水量': [0, 5, 10, 0]
}
df = pd.DataFrame(data)dfの結果 ※Google Colabで表示

温度データをピボットする場合は次のように記入します。
pivot_df = df.pivot(index='日付', columns='都市', values='温度')日付ごとに都市を列として、それぞれの温度を値として持つ新しいデータフレームを作成することができます。
pivot_dfの結果 ※Google Colabで表示

pandasによるファイル操作
CSVファイルからデータフレームを作成 : read_csv( )
pd.read_csv( )でCSVファイルを読み込んで、データフレームを作成することができます。
データフレームをリストや辞書で直接作成することは、データ数が多いと大変です。
また、pandasを活用する場合は、すでに収集しているデータを解析するケーが多いと思います。
そのため、データフレームを作成する場合はCSVファイルから作成する方法が基本になります。
引数は「CSVファイルのパス」を入れます。
データの区切り文字はデフォルトでカンマ「,」になってますが、「sep=」で指定することもできます。
# CSVファイルからデータフレームを作成
df = pd.read_csv("CSVファイルのパス")
# データの区切り文字を指定
df = pd.read_csv("CSVファイルのパス", sep=";")データフレームをCSVファイルへ書き出し : to_csv()
to_csv( )でデータフレームをCSVファイルに書き込むことができます。
引数は「CSVファイルのパス」を入れます。
データの区切り文字はデフォルトでカンマ「,」になってますが、「sep=」で指定することもできます。
# CSVファイルに書き出し
df.to_csv("CSVファイルのパス")
# データの区切り文字を指定
df.to_csv("CSVファイルのパス", index=False, sep=";")Q&A
pandasとは何ですか?
pandasはPythonでデータ分析を行うためのオープンソースライブラリで、データ構造とデータ操作ツールを提供します。
データをシリーズ(Series)やデータフレーム(DataFrame)という形式で処理します。
DataFrameとSeriesの違いは何ですか?
DataFrameは2次元のラベル付きデータ構造です。
Seriesは1次元のラベル付き配列です。
pandasの主な使い道は何ですか?
pandasは下記の使い方で活躍します。
- データの前処理(読み込み、結合、欠損値処理、データクリーニングなど)
- データの集計・分析(グループ化、ピボット、相関係数の計算など)
- データの可視化(pandasと連携して使えるmatplotlibなど)
- 時系列データの処理
おすすめ書籍


まとめ
本記事では、pandasの基本的な使い方をわかりやすく解説しました。
Pythonでのデータ分析において、pandasはデータ操作と分析のための非常に強力なライブラリですので、使い方を覚えておきましょう。
紹介したサンプルコードをコピペすれば、簡単にコードに使用することができますので、ぜひご利用ください!
紹介した内容以外にも下記のような関数やメソッドがあります。
- データフレームの結合 : merge()
- one-hotエンコーディング : get_dummies() など
今後追加していこうと思います。
Pythonを効率的に学習するために
Pythonの学習方法は、書籍やyoutube、スクールなどがありますが、一番のおすすめはオンラインスクールでの学習です。
オンラインスクールを勧める理由は以下の通り。
- 学習カリキュラムが整っているので、体系的に学ぶことができる。
- 時間や場所を選ばずに、自分のペースで学習できる。
- 学習で詰まったときに、気軽に質問できる環境がある。
オンラインスクールについてはコチラの記事で紹介しています。
⇒ これで決まり!Pythonオンラインスクール おすすめ3社を厳選!
2024年10月1日から給付制度が拡充され、最大80%給付されるスクールもあります。
Python学習を効率的に進めるために、スクールの検討をしてみてください。
おすすめオンラインスクール
コスト重視:デイトラ![]()
AIスキル重視:Aidemy PREMIUM ![]()
転職重視:キカガク![]()
最後まで読んでいただきありがとうございます!
ご意見、ご感想があれば、コメントを頂けるとうれしいです!!
