
- Pythonの基礎を勉強したけど、次に何しよう?
- Webスクレイピングってどうやるんだろう?
- サイトから情報収集するのに、コピペに時間がかかって困る。効率化できないかな?
こんな悩みを解決します!!
Webスクレイピングってご存じですか?
簡単に言うと、Webサイトの情報を自動で取得することです。
取得できる情報はWebサイトのタイトルや本文、画像、リンクURLなどで、Webサイト上に表示されている情報はほぼ取得できます。
Webスクレイピングは流れがわかればすぐできるようになります。
そのため、Pythonの基礎を覚えた後に挑戦する題材としては適していると思います。
また、複数のページから情報を取得するできるため、仕事でWeb上から情報収集する際、データを何度もコピペする必要がなくなります!
ココナラでWebスクレイピングの案件も出品されているので、うまくいけば副業として収益を得ることもできます。
本記事では、PythonでのWebスクレイピングのやり方を3stepでわかりやすく解説します。
Webスクレイピングをする際の注意点も記載しているので、最後まで読んでいただけると嬉しいです!!
\ 学習時間をムダにしたくないなら /
おすすめオンラインスクール
Pythonを効率的に学習するには、オンラインスクールを活用するのがおすすめです。
おすすめオンラインスクールはこちらの記事で紹介しています。
⇒ これで決まり!Pythonオンラインスクール おすすめ3社を厳選!
Webスクレイピングとは
Webスクレイピングについて、おさらいです。
Webスクレイピングとは、Webサイトの情報を自動で取得することです。
取得できる情報はWebサイトのタイトルや本文、画像、リンクURLなどです。
Webスクレイピングをうまく活用できれば、仕事や趣味などでの情報収集を効率的に行えます。
Webスクレイピングの流れ次の通りです。
- Webサイトのhtmlを取得
- データ抽出
- 抽出したデータを保存
【重要】Webスクレイピングを始める前に
Webスクレイピングを始める前に、Webスクレイピングしても大丈夫なサイトか確認する必要があります。
WebスクレイピングNGなサイトをスクレイピングすると、アクセスできなくなる可能性があります。
WebスクレイピングNGなサイト例はコチラです。
- Amazon
- 楽天市場
- YouTube
- Yahoo!ファイナンス
- Wantedly
- NewsPicks
- メルカリ など
今回紹介する方法でのWebスクレイピングがNGでも、専用APIを使用すればデータ抽出できるサイトもあります。
WebスクレイピングNGか確認する方法
①Webサイトの利用規約を確認する。
WebスクレイピングNGか確認するには、Webサイトの利用規約を確認してください。
利用規約は文章量が多いので、上から下まで読み込むのは大変です。
Webスクレイピングに関する項目を見つけるには、関連するキーワードで検索すると簡単です。
- 自動
- ロボット
- クローリング
- スクレイピング
- auto
- robot
- crawling
- scraping など
②robot.txtを確認する
robots.txt とは、検索エンジンのクローラに対して、Webサイトのどこ にアクセスしてよいかを伝えるファイルのことです。
クローラとは、Webサイトを自動的に巡回して、公開されている文書や画像などのデータを収集するプログラムのことです。
robots.txt には自動でアクセスしてよいURLが記載されています。
スクレイピングは、robots.txt に記載されているURLに対して行いましょう。
「requests」と「beautifulsoup」を使ったWebスクレイピング
ライブラリのインストール
PythonでWebスクレイピングする方法の1つとして、「requests」と「beautifulsoup」を使った方法があります。
「requests」と「beautifulsoup」をインストールしていない方は下記コマンドをコマンドプロンプトで実行しましょう。
pip install requests
pip install beautifulsoup4ソースコード例
今回は私のプロフィール文を抽出するコードです。
############################
## ライブラリのインポート ##
############################
# スクレイピング用
from time import sleep
from bs4 import BeautifulSoup
import requests
# データ保存用
import pandas as pd
####################
## スクレイピング ##
####################
# 対象サイトのURLを格納する
url = "https://pythonsoba.tech/profile/"
# requestsを使用して、htmlを取得。変数rに格納
r = requests.get(url)
# 対象サイトへ負荷をかけないように、1sec待機
sleep(1)
# 取得結果を解析してsoupに格納
soup = BeautifulSoup(r.content, "html.parser")
# 本文が入っている「entry-content」クラスを抽出
contents = soup.find("div", class_="entry-content")
# 本文を抽出
data_list = contents.find_all("p")
# データフレームに格納するため、抽出結果をまとめる
data_result = []
for data in data_list:
# 抽出した本文を辞書に格納する
data_set = {
'本文': data.text
}
# 取得した辞書をd_listに格納する
data_result.append(data_set)
##################
## データを保存 ##
##################
# data_resultを、データフレームに格納
df = pd.DataFrame(data_result)
# to_csv()を使って、データフレームをCSV出力する
df.to_csv("test.csv",index=None,encoding="utf-8-sig")STEP1 Webサイトのhtmlを取得
ポイント
- requests.get()でWebサイトのhtmlを取得する
- スリープを入れる
requests.get()でWebサイトのhtmlを取得する
# 対象サイトのURLを格納する
url = "https://pythonsoba.tech/profile/"
# requestsを使用して、htmlを取得。変数rに格納
r = requests.get(url)Webサイトに直接アクセスして、指定したURLのhtmlを取得します。
変数 r に格納したURLを確認したいときは、r.textやr.contentで出力します。
スリープを入れる
# 対象サイトへ負荷をかけないように、1sec待機
sleep(1)Webサイトに連続でアクセスすると、サーバーに負荷がかかります。
サーバーに負荷をかけすぎると、サーバーが落ちる可能性があります。
また、悪質な行為と判断されればサーバーからブロックされたり、最悪、罪に問われる可能性もあります。
必ず1秒程度のスリープを入れましょう。
STEP2 データ抽出 BeautifulSoup
ポイント
- requestsで取得したhtmlを解析する
- 欲しい情報がhtml内のどこにあるか確認する
- 情報を抽出する
requestsで取得したhtmlを解析する
# 取得結果を解析してsoupに格納
soup = BeautifulSoup(r.content, "html.parser")BeautifulSoupを使用して、変数 soup に解析結果を格納します。
html.parse は解析手段をしているのですが、基本はこのままでOKです。
欲しい情報がhtml内のどこにあるか確認する
欲しい情報がhtml内のどこにあるか確認するには、ブラウザ(edgeやchromeなど)で直接htmlを見る必要があります。
本記事ではchromeで説明します。
確認したいWebサイト上で右クリックをし、「検証」を押します。
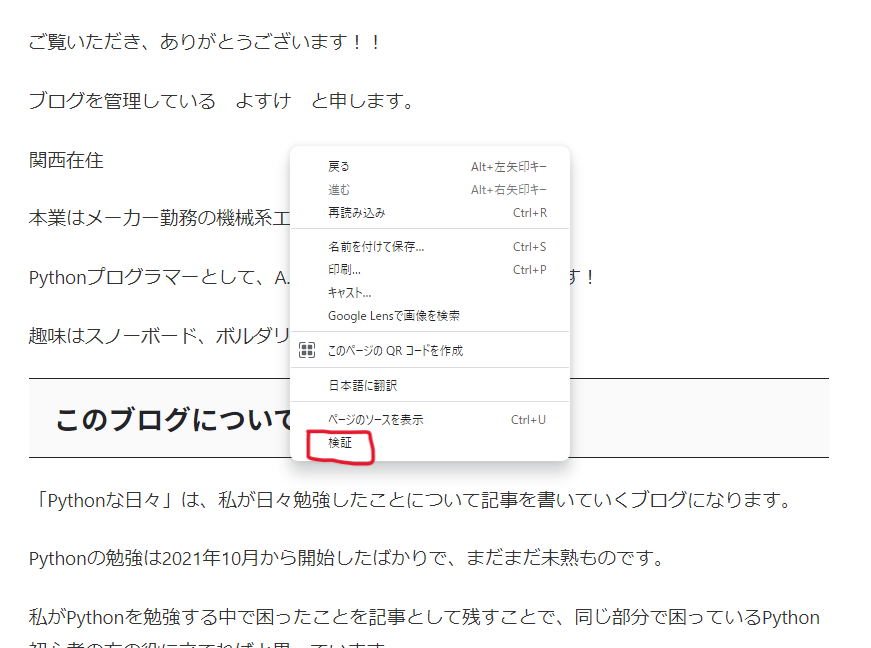
右側にWebサイトのhtmlが表示されるので、下記赤枠のボタンを押します。
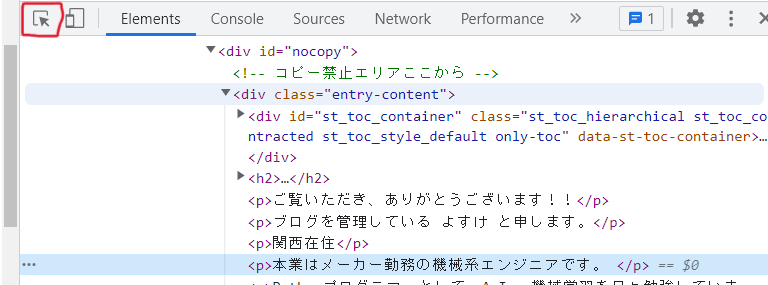
Webサイトの文章などにカーソルを合わせると、htmlのどこに書かれているか表示されるので、タグ(<dev class="entry-content">や<p>のこと)を確認します。
情報を抽出する
# 本文が入っている「entry-content」クラスを抽出
contents = soup.find("div", class_="entry-content")
# 本文を抽出
data_list = contents.find_all("p")
# データフレームに格納するため、抽出結果をまとめる
data_result = []
for data in data_list:
# 抽出した本文を辞書に格納する
data_set = {
'本文': data.text
}
# 取得した辞書をd_listに格納する
data_result.append(data_set)欲しい情報のタグを確認したら、find()やfind_all()でデータを抽出します。
- find() : データを最初の1つだけ抽出します。
- find_all() : 該当するすべてのデータを抽出します。抽出結果はリストとして出力されます。
find()やfind_all()で取得したデータは 「.text」 でテキストデータを抽出することができます
今回の例では取得したい本文がタグ<p>内にあり、本文以外のデータを抽出したくなかったため、2段階で抽出をしています。
タグ<dev>のクラス"entry-content"を抽出してから、その結果からさらにタグ<p>を抽出する流れです。
抽出した結果は後で保存しやすいように、辞書に格納しています。
STEP3 抽出したデータの保存
ポイント
- pandasのデータフレームを使用して、csvに保存する
pandasのデータフレームを使用して、csvに保存する
# data_resultを、データフレームに格納
df = pd.DataFrame(data_result)
# to_csv()を使って、データフレームをCSV出力する
df.to_csv("test.csv",index=None,encoding="utf-8-sig")SETP2で抽出したデータをデータフレームにしてから、csvで保存します。
保蔵方法は今回紹介している方法以外でもOKです。
活用しやすいように、データ処理や保存をしましょう!
よくある質問
Webスクレイピングって何?
Webスクレイピングは、ウェブサイトからデータを自動的に収集する技術のこと。
Pythonには、HTMLやXMLからデータを抽出するためのライブラリが多数あり、これらを利用してWebページの情報を取得し、解析することができます。
Webスクレイピングのメリットは?
Webサイトから手動で情報を取得するよりも、効率的に情報を取得することができます。
Webスクレイピングをするには、どんなライブラリを使うの?
PythonのWebスクレイピングでは、BeautifulSoupやScrapy、Requests、Seleniumなどのライブラリを使用します。
Webスクレイピングをするときに注意すべきことは?
Webスクレイピングをするときは、Webサイトの利用規約に従うように注意してください。
また、Webサイトのサーバーに負荷をかけないように、適切な時間間隔を設定することも大切です。
まとめ
PythonでのWebスクレイピングのやり方を3stepでわかりやすく解説しました。
- Webサイトのhtmlを取得
- データ抽出
- 抽出したデータを保存
Webサイトに合わせて、「2.データ抽出」で工夫が必要ですが、基本の流れは変わりません。
また、Webスクレイピングする際は下記注意点を意識してください。
- WebスクレイピングNGか確認する
- スリープを入れる
最後まで読んでいただきありがとうございます!
ご意見、ご感想があれば、コメントを頂けるとうれしいです!!
