
- Pythonで機械学習を始めたいけれど、どこから手をつければいいのかわからない
- scikit-learnの使い方を学びたいけれど、公式ドキュメントだけでは難しく感じる
- データ前処理からモデル構築、評価までの一連の流れを実践的に理解したい
こんな悩みを解決します。
scikit-learnは、Pythonで機械学習を行うためのライブラリで、シンプルなコードで高度なモデルを実装できます。
データの前処理、モデルの選択、学習、評価まで一貫して行えるため、初心者でも効率的に機械学習を習得できます。
この記事では、scikit-learnの基本的な使い方から、データ前処理、モデル構築、評価までの実践的な流れについて、わかりやすく解説します。
この記事を読み進めれば、scikit-learnを活用して機械学習の基礎をしっかりと身につけ、実際のデータを使ったモデル構築がスムーズにできるようになります。
scikit-learnとは、Pythonで機械学習を行うためのライブラリのこと

scikit-learnの概要
scikit-learnとは、Pythonで機械学習を行うためのライブラリです。
読み方は「サイキットラーン」です。
scikit-learnは多くの教師あり学習・教師なし学習のアルゴリズムが実装されていて、データの前処理からモデル評価まで幅広い機能を備えています。
scikit-learnの主な特徴
scikit-learnの主な特徴は次の通りです。
- 様々なアルゴリズムが使える
- シンプルで一貫性のあるAPI
- 充実したドキュメントとサンプルコード
様々なアルゴリズムが使える
主に使用できるアルゴリズムには以下のようなものがあります。
- 分類:ロジスティック回帰、ランダムフォレスト、SVM、決定木など
- 回帰:線形回帰、SVR、ランダムフォレスト回帰、勾配ブースティングなど
- クラスタリング:K-means、DBSCAN、階層型クラスタリングなど
- 次元削減:PCA、t-SNE、因子分析など
- 前処理:標準化、正規化、エンコーディングなど
シンプルで一貫性のあるAPI
どのアルゴリズムも同じような手順で利用できるため、学習コストが低く、様々なモデルを試しやすいです。
充実したドキュメントとサンプルコード
公式ドキュメントが非常に充実しており、多くのサンプルコードが提供されているため、初心者でも理解しやすいです。
機械学習とは
機械学習(Machine Learning)は、コンピューターが大量のデータを分析し、そこからパターンや規則性を学習することで、予測や意思決定の精度を向上させる技術です。
機械学習の例として、次のようなものがあります。
- 写真の中の物体や人物を識別する画像認識
- 人間の言語を理解し、翻訳や要約を行う自然言語処理
- 過去のデータから将来の傾向を予測する予測分析
機械学習の種類
機械学習は大きく分けて以下の種類があります。
- 教師あり学習 (Supervised Learning):正解ラベル付きのデータを使って学習する
- 教師なし学習 (Unsupervised Learning): 正解ラベルのないデータを使って学習する
- 半教師あり学習(Semi-supervised Learning):少量の教師データと大量の未ラベルデータを組み合わせる
- 強化学習(Reinforcement Learning):行動と報酬のフィードバックから学習
- ディープラーニング(Deep Learning):多層ニューラルネットワークを使用した学習
scikit-learnは主に教師あり学習と教師なし学習に焦点を当てています。
機械学習の流れ
機械学習の基本的な流れは以下の通りです。
- データ収集:問題に関連するデータを集める
- データ前処理:欠損値の処理、特徴量のスケーリング、カテゴリデータの変換など
- データ分割:訓練データとテストデータに分ける
- モデル選択:問題に適したアルゴリズムを選ぶ
- モデル訓練:訓練データを使ってモデルのパラメータを最適化する
- モデル評価:テストデータでモデルの性能を評価する
- パラメータチューニング:モデルの性能を向上させるためにパラメータを調整する
- 予測・推論:新しいデータに対して予測を行う
機械学習では、特徴量からターゲットを予測します。
特徴量とは、モデルが「何をもとに予測するか」という情報です。
ターゲットとは、モデルが予測したい「目的の値」です。
scikit-learnは、これらのステップを簡単に実装できるように設計されています。
scikit-learnの使い方
ライブラリのインストール
scikit-learnをインストールしていない方は、下記コマンドをコマンドプロンプトで実行しましょう。
pip install scikit-learnscikit-learnを使用するときは、仮想環境で行うことが推奨されています。
仮想環境を使うと、プロジェクトごとに異なるバージョンのライブラリを使用でき、環境の衝突を避けられます
仮想環境の作成例は次の通りです。
# 仮想環境の作成(仮想環境名は変更可能)
python -m venv sklearn_env
# 仮想環境の有効化(Windows)
sklearn_env\Scripts\activate
# scikit-learnのインストール
pip install -U scikit-learn-U オプションをつけることで、依存ライブラリも含めて最新バージョンに更新することができます。
仮想環境については、こちらの記事で解説しています。
⇒【Python仮想環境】初心者でもできるvenvによる仮想環境作成方法を解説!
numpyやpandas、 matplotlibなどと組み合わせることが多いため、必要に応じてこれらもインストールしておくと便利です。
pip install numpy pandas matplotlibGoogle Colabでの使用
Google Colab(Colaboratory)は、ブラウザ上でPythonコードを実行できる無料の開発環境です。
scikit-learnがプリインストールされているので、すぐに使用できます。
Google ColabはGPUも無料で使えるため、機械学習を学ぶのに最適です。
Google Colabについては、こちらの記事で解説しています。
⇒ 【Google Colabの使い方】ブラウザ上のPython開発環境を解説!Google Driveへの連携方法も紹介
ライブラリの使用方法
scikit-learnは下記のようにインポートすることができます。
import sklearn上記のインポート方法では、scikit-learnのパッケージ自体は利用可能になりますが、基本的に各モジュールを個別にインポートします。
モジュールのインポート例は次の通りです。
(1) データセットの読み込み
from sklearn.datasets import load_iris
iris = load_iris() # iris データセットを読み込む(2) データの分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)(3) 前処理(特徴量の標準化)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)(4) 機械学習モデル
線形回帰
from sklearn.linear_model import LinearRegressionロジスティック回帰
from sklearn.linear_model import LogisticRegressionサポートベクターマシン
from sklearn.svm import SVCランダムフォレスト
from sklearn.ensemble import RandomForestClassifierk近傍法
from sklearn.neighbors import KNeighborsClassifier(5) モデル評価
from sklearn.metrics import accuracy_score(6) クラスタリング
from sklearn.cluster import KMeansscikit-learnのメリット・デメリット
scikit-learnのメリット
scikit-learnのメリットは次のとおりです。
- 使いやすさと直感的なAPI
- 強力なデータ前処理ツール
- 軽量かつ依存関係が少ない
使いやすさと直感的なAPI
scikit-learnは一貫性のあるシンプルなAPIを持ち、初心者でも直感的に利用できます。
.fit()、.predict()、.score() などの統一されたインターフェースにより、モデルの学習や評価が容易です。
強力なデータ前処理ツール
scikit-learnは、標準化 (StandardScaler)や正規化 (MinMaxScaler)、欠損値補完 (SimpleImputer)、カテゴリ変数のエンコーディング (OneHotEncoder) など、データの前処理機能が充実しています。
pipeline機能を使うことで、前処理からモデル学習までを一貫して実装可能です。
軽量かつ依存関係が少ない
scikit-learnは、NumPy、SciPy、Joblib などの最小限の依存関係で動作するため、環境構築が比較的容易に行うことができます。
TensorFlowやPyTorchと比べて、軽量で高速な処理が可能です。
scikit-learnのデメリット
scikit-learnのデメリットは次のとおりです。
- ディープラーニングのサポートがない
- 大規模データセットには不向き
- モデルのカスタマイズが難しい
ディープラーニング(深層学習)のサポートがない
scikit-learnは、ニューラルネットワークを用いたディープラーニング(深層学習)には対応していません。
ディープラーニングを扱う場合は、TensorFlowやPyTorchを使用する必要があります。
大規模データセットには不向き
scikit-learnは主にメモリ内処理を前提としているため、数百万件以上のデータを扱う場合、パフォーマンスが低下する可能性があります。
Spark MLlibやDask など、大規模データ向けのライブラリと組み合わせることで対応できます。
モデルのカスタマイズが難しい
scikit-learnのアルゴリズムはブラックボックス的な部分が多く、低レベルの調整が難しいです。
カスタム損失関数や独自の学習アルゴリズムを導入する場合、他のライブラリ(PyTorchやTensorFlowなど)の方が適しています。
他の機械学習ライブラリとの比較
| ライブラリ | 特徴 | 用途 |
|---|---|---|
| scikit-learn | 簡潔なAPI、豊富な機能、良いドキュメント | 伝統的な機械学習アルゴリズム、小〜中規模データ |
| TensorFlow | 柔軟なアーキテクチャ、分散処理、本番デプロイ | ディープラーニング、大規模データ、モバイルデプロイ |
| PyTorch | 動的計算グラフ、研究向け、Pythonライク | 研究開発、ディープラーニング実験 |
| XGBoost | 勾配ブースティングに特化、高速、高精度 | 構造化データの予測タスク、コンペティション |
| LightGBM | 非常に高速、メモリ効率が良い | 大規模構造化データ、高速な学習が必要な場合 |
scikit-learnは、特に初心者や一般的な機械学習タスクにおいて、最も使いやすいライブラリの一つです。
scikit-learnによる機械学習の基本フロー
機械学習の基本的な流れは次のとおりです。
- データ収集:問題に関連するデータを集める
- データ前処理:欠損値の処理、特徴量のスケーリング、カテゴリデータの変換など
- データ分割:訓練データとテストデータに分ける
- モデル選択:問題に適したアルゴリズムを選ぶ
- モデル訓練:訓練データを使ってモデルのパラメータを最適化する
- モデル評価:テストデータでモデルの性能を評価する
- パラメータチューニング:モデルの性能を向上させるためにパラメータを調整する
- 予測・推論:新しいデータに対して予測を行う
ここでは、scikit-learnの基本的な使い方として、①③⑤⑥に関するサンプルコードを紹介します。
データは、scikit-learnに含まれているデータセット「Iris」を使います。
# インポート
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# データの読み込み
iris = load_iris()
X = iris.data # 特徴量
y = iris.target # ターゲット
# データを学習用とテスト用に分割 (80%を学習用、20%をテスト用)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルのインスタンス化
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# モデルの学習
clf.fit(X_train, y_train)
# 予測
y_pred = clf.predict(X_test)
# 評価
accuracy = accuracy_score(y_test, y_pred)
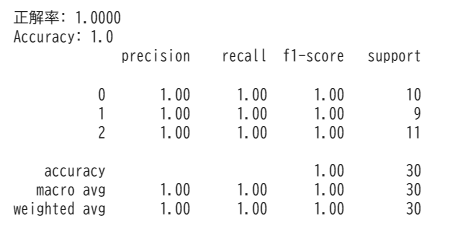
print(f"正解率: {accuracy:.4f}")
# 詳細な評価レポート
print(classification_report(y_test, y_pred))出力結果 ※Google Colabで表示
学習データとテストデータの用意
機械学習では、モデルの学習に使用するデータ(学習データ)と、学習済みモデルの性能を評価するためのデータ(テストデータ)を用意する必要があります。
scikit-learnのtrain_test_split関数を使うと、簡単にデータを分割できます。
# インポート
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# データの読み込み
iris = load_iris()
X = iris.data # 特徴量
y = iris.target # ターゲット
# データを学習用とテスト用に分割 (80%を学習用、20%をテスト用)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)test_size:テストデータの割合(0.2は20%の意味)
random_state:乱数のシード値(再現性のために設定)毎回同じようにデータを分割できるため、結果の再現性が保たれます。
モデルの訓練・評価の流れ
scikit-learnでは、以下の手順でモデルの訓練と評価を行います。
- モデルのインスタンス化
- 訓練データでモデルを学習(fit)
- テストデータで予測(predict)
- 評価(scoreやmetrics)
この手順はどのアルゴリズムでも同じパターンで使用できます。
# インポート
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# モデルのインスタンス化
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# モデルの学習
clf.fit(X_train, y_train)
# 予測
y_pred = clf.predict(X_test)
# 評価
accuracy = accuracy_score(y_test, y_pred)
print(f"正解率: {accuracy:.4f}")
# 詳細な評価レポート
print(classification_report(y_test, y_pred))データの読み込みと前処理
実務ではCSVファイルやデータベースからデータを読み込むことがあります。
pandasを使った、CSVファイルの読み込み方法を紹介します。
# CSVファイルからのデータ読み込み(pandas使用)
import pandas as pd
df = pd.read_csv('データファイル.csv')
# 特徴量とターゲットの分離
X = df.drop('target_column', axis=1)
y = df['target_column']上記の「データファイル.csv」は、複数の特徴量と、列ラベル「target_column」のターゲットから構成されています。
pandasの使い方については、こちらの記事で解説しています。
⇒ pandasの使い方をわかりやすく解説!!データフレームを使いこなそう!サンプルコード付き!
読み込んだデータはそのまま使用せず、前処理を行います。データの前処理は、機械学習の精度向上に重要な作業です。
前処理にはデータクリーニングや欠損値の処理、データ変換などがあります。
前処理の詳細は後述します。
モデルの保存と再利用方法
学習済みのモデルは、joblibを使って保存し、後で再利用することができます。
joblibとは、Pythonでデータサイエンスや機械学習のワークフローを効率化するためのライブラリです。
# インポート
import joblib
# モデルを保存
joblib.dump(model,'trained_model.joblib')
# 保存したモデルを読み込む
loaded_model = joblib.load('trained_model.joblib')データ前処理
機械学習の精度を高めるためには、適切なデータ前処理が不可欠です。
実際のデータには欠損値や異常値が含まれていたり、カテゴリ変数が数値化されていなかったりするため、scikit-learnを用いた前処理を行い、分析しやすい形に整えます。
データクリーニング
データクリーニングは、データセット内の誤りや不整合を修正するプロセスです。
具体的には、以下のような処理を行います。
- 重複データの削除:同じデータが複数存在する場合、それらを削除します。
- 誤字脱字の修正:データ入力ミスによる誤字脱字を修正します。
- 表記揺れの統一: 例えば、「株式会社」と「(株)」のように、同じ意味を持つ異なる表記を統一します。
- データ型変換:数値データ、カテゴリデータなど、各列が適切なデータ型になっているかを確認し、必要に応じて変換します。
欠損値の処理
データセットには、特定の値が欠損しているケースがあります。
この欠損値が機械学習モデルの性能が低下する原因となるため、適切な処理が必要です。
scikit-learnには複数の欠損値処理方法が提供されています。
欠損値の補完
欠損値を何らかの値で埋めることを補完といいます。
scikit-learnでは、以下の補完方法が利用できます。
- SimpleImputer:平均値、中央値、最頻値、または定数で欠損値を補完します。
- KNNImputer:K近傍法を用いて、欠損値を持つデータ点に最も近いK個のデータ点の値から欠損値を推定します。
# インポート
from sklearn.impute import SimpleImputer, KNNImputer
import numpy as np
import pandas as pd
# サンプルデータの作成
data = pd.DataFrame({
'A': [1, 2, np.nan, 4],
'B': [np.nan, 2, 3, 4],
'C': [10, np.nan, 30, 40]
})
# SimpleImputer (平均値)を用いた補完
simple_imputer = SimpleImputer(strategy='mean')
filled_data_sim = simple_imputer.fit_transform(data)
# KNNImputer(k=2)を用いた補完
knn_imputer = KNNImputer(n_neighbors=2)
filled_data_knn = knn_imputer.fit_transform(data)
# 出力
print("元データ:")
print(data)
print("\nSimpleImputerで補完したデータ:")
filled_df_sim = pd.DataFrame(filled_data_sim, columns=data.columns, index=data.index) # 出力フォーマットを合わせる
filled_df_sim = filled_df_sim.round(1)
print(filled_df_sim)
print("\nKNNImputerで補完したデータ:")
filled_df_knn = pd.DataFrame(filled_data_knn, columns=data.columns, index=data.index) # 出力フォーマットを合わせる
filled_df_knn = filled_df_knn.round(1)
print(filled_df_knn)出力結果 ※Google Colabで表示

各コマンドの引数は次の通りです。
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(
missing_values=np.nan, # 欠損値として扱う値(デフォルト: np.nan)
strategy="mean", # 補完方法: 'mean', 'median', 'most_frequent', 'constant'
fill_value=None, # strategy='constant' のときの補完値(デフォルト: None)
copy=True, # 元のデータを変更せず、新しいデータを作成(デフォルト: True)
add_indicator=False, # True の場合、欠損値があったかどうかを示す特徴量を追加
keep_empty_features=False, # 空の特徴量を保持するか(デフォルト: False)
)from sklearn.impute import KNNImputer
imputer = KNNImputer(
missing_values=np.nan, # 欠損値として扱う値(デフォルト: np.nan)
n_neighbors=5, # 近傍点の数(デフォルト: 5)
weights="uniform", # 'uniform'(一様重み)または 'distance'(距離に応じた重み)
metric="nan_euclidean", # 距離計算の方法(デフォルト: nan_euclidean)
copy=True, # 元のデータを変更せず、新しいデータを作成(デフォルト: True)
)欠損値の除去
欠損値を含む行または列をデータセットから削除します。
ただし、データの量が大幅に減少する可能性があるため、注意が必要です。
欠損値の除去にはpandasを使用します。
# インポート
import pandas as pd
import numpy as np
# サンプルデータ (欠損値を含む)
df = pd.DataFrame({'A': [1, 2, np.nan], 'B': [4, np.nan, 6], 'C': [7, 8, 9]})
# 欠損値を含む行を削除
df_dropped = df.dropna()
# 特定の列(例:'B')に欠損値がある行を削除
df_dropped_subset = df.dropna(subset=['B'])
# 欠損値を含む列を削除
df_dropped_column = df.dropna(axis=1)
# 結果の確認
print("元のデータ:\n", df)
print("\n欠損値を含む行を削除:\n", df_dropped)
print("\n'B'列に欠損値がある行を削除:\n", df_dropped_subset)
print("\n欠損値を含む列を削除:\n", df_dropped_column)異常値・外れ値の処理
異常値・外れ値とは、他のデータと大きく異なる値のことです。
データに異常値が存在すると、分析やモデルの予測精度に悪影響を与える可能性があります。
機械学習を行う前に、異常値を適切に処理することは、機械学習の精度向上に重要な作業です。
IQR(四分位範囲)法:上下の四分位範囲を超えるデータを異常値として除外または変換
IQR(Interquartile Range)は、データの第3四分位数(75パーセンタイル)から第1四分位数(25パーセンタイル)を引いた値です。
IQR法では、以下の範囲から外れるデータを異常値とみなし、データを除去します。
- 下限: 第1四分位数 - 1.5 * IQR
- 上限: 第3四分位数 + 1.5 * IQR
異常値を完全に除外する代わりに、平均値や中央値などの代替値で置き換える方法もあります。
scikit-learn自体にはIQR法の関数はありません。pandasやnumpyで異常値処理をしてから、モデルにデータを使用します。
pandasを使用した例
# インポート
import pandas as pd
# サンプルデータ作成
data = {'value': [10, 12, 13, 12, 11, 300, 14, 13, 12, 11]}
df = pd.DataFrame(data)
# Q1, Q3の計算
Q1 = df['value'].quantile(0.25)
Q3 = df['value'].quantile(0.75)
IQR = Q3 - Q1
# 異常値の範囲を定義
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 異常値を除外したデータフレーム
df_filtered = df[(df['value'] >= lower_bound) & (df['value'] <= upper_bound)]
# 結果の確認
print("元のデータ:\n", df)
print("\n異常値を除いたデータ:\n", df_filtered)出力結果 ※Google Colabで表示

numpyを使用した例
# インポート
import numpy as np
# サンプルデータ
data = np.array([10, 12, 13, 12, 11, 300, 14, 13, 12, 11])
# Q1, Q3の計算
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
IQR = Q3 - Q1
# 異常値の範囲を定義
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 異常値を除外
filtered_data = data[(data >= lower_bound) & (data <= upper_bound)]
# 結果の確認
print("元のデータ:", data)
print("異常値を除いたデータ:", filtered_data)出力結果 ※Google Colabで表示
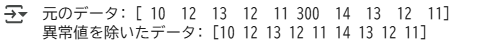
Zスコア(標準化スコア)法:絶対値が3を超えるデータを異常値とみなす
Zスコアは、データの各値が、平均から標準偏差の何倍離れているかを示す指標です。
Zスコアの絶対値が3を超えるデータを異常値とみなすのが一般的です。
異常値の対処法には、完全に除外する方法と、平均値や中央値などの代替値で置き換える方法があります。
sklearn.preprocessing.StandardScalerを使ってZスコア標準化が可能です。
異常値の検出には、scipy.stats.zscoreなども活用できます。
sklearn.preprocessing.StandardScaler を使用した例
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
# サンプルデータ作成
data = {'value': [10, 10, 10, 10, 10, 300, 10, 10, 10, 10]}
df = pd.DataFrame(data)
# Zスコア標準化
scaler = StandardScaler()
z_scores = scaler.fit_transform(df[['value']])
# 絶対値が3を超えるZスコアを持つ行を外れ値とみなす
df['z_score'] = z_scores
df_filtered = df[df['z_score'].abs() < 3]
# 結果の確認
print("元のデータ:\n", df)
print("\n異常値を除いたデータ:\n", df_filtered)scipy.stats.zscore を使用した例
# インポート
import numpy as np
import pandas as pd
from scipy.stats import zscore
# サンプルデータ作成
data = {'value': [10, 10, 10, 10, 10, 300, 10, 10, 10, 10]}
df = pd.DataFrame(data)
# Zスコア計算
df['z_score'] = zscore(df['value'])
# 絶対値が3以下のデータを抽出(異常値を除外)
df_filtered = df[df['z_score'].abs() < 3]
# 結果の確認
print("元のデータ:\n", df)
print("\n異常値を除いたデータ:\n", df_filtered)特徴量エンジニアリング
特徴量エンジニアリングとは、機械学習アルゴリズムに入力するデータ(特徴量)を加工・選別・変換し、モデルの精度向上を目指すプロセスです。
特徴量作成
特徴量作成とは、既存の特徴量から新しい特徴量を作り出すことです。
特徴量作成の例として、次のものがあります。
- 日付データから「曜日」や「月」などの特徴量を作成する
- テキストデータから単語の出現頻度やTF-IDFなどの特徴量を作成する
- 複数の特徴量を組み合わせて新しい特徴量を作成する(例:身長と体重からBMIを計算する)
scikit-learnでは、PolynomialFeaturesなどを使うことで、特徴量のべき乗や交互作用項を自動的に生成することができます。
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
# サンプルデータ(2特徴量×5サンプル)
X = pd.DataFrame({
'x1': [1, 2, 3, 4, 5],
'x2': [2, 4, 6, 8, 10]
})
# 2次の多項式特徴量を作成
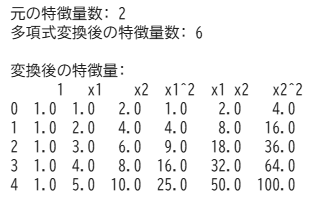
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# 結果の確認
print(f"元の特徴量数: {X.shape[1]}")
print(f"多項式変換後の特徴量数: {X_poly.shape[1]}")
print("\n変換後の特徴量:\n", pd.DataFrame(X_poly, columns=poly.get_feature_names_out()))出力結果 ※Google Colabで表示
特徴量選択
特徴量選択とは、モデルの学習に有効な特徴量を選び出すことです。
不要な特徴量やノイズとなる特徴量を削除することで、モデルの性能を向上させ、過学習を防ぐことができます。
scikit-learnでは、以下の様な特徴量選択の手法が提供されています。
- 分散に基づく選択 (VarianceThreshold):分散が低い特徴量(値の変化が少ない特徴量)は情報量が少ないとみなし、削除します
- 単変量特徴量選択 (SelectKBest、SelectPercentile):各特徴量とターゲット変数との間の統計的な関係を評価し、スコアの高い特徴量を選択します
- 再帰的特徴量削減 (RFE):モデルを繰り返し学習させ、重要度の低い特徴量を削除していくことで、最適な特徴量の組み合わせを見つけます
- SelectFromModel:他のモデルを使って特徴量の重要度を計算し、それをもとに特徴量を選択します
分散に基づく選択の例
# インポート
import numpy as np
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
# サンプルデータ(4特徴量 × 6サンプル)
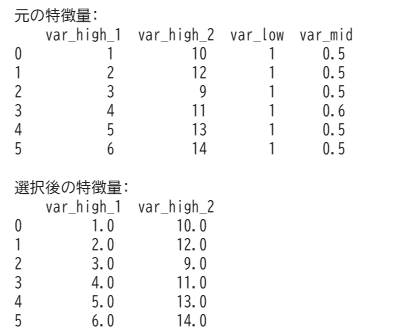
X = pd.DataFrame({
'var_high_1': [1, 2, 3, 4, 5, 6], # 分散大
'var_high_2': [10, 12, 9, 11, 13, 14], # 分散大
'var_low': [1, 1, 1, 1, 1, 1], # 分散ゼロ
'var_mid': [0.5, 0.5, 0.5, 0.6, 0.5, 0.5] # 分散小(しきい値以下)
})
# 分散が0.1未満の特徴量を除外
selector = VarianceThreshold(threshold=0.1)
X_selected = selector.fit_transform(X)
# 結果の確認
print("元の特徴量:\n", X)
print("\n選択後の特徴量:\n", pd.DataFrame(X_selected, columns=X.columns[selector.get_support()]))出力結果 ※Google Colabで表示
特徴量のスケーリング
機械学習において、異なるスケールのデータを扱う場合、特徴量のスケーリングが必要です。
特徴量間のスケール(値の範囲)を揃えることで、モデルが特定の変数の影響を過度に受けないようにすることができます。
スケーリングの方法は次のとおりです。
- 標準化(Standardization)
- 正規化(Normalization)
- ロバストスケーリング(RobustScaler)
標準化(Standardization):平均0、分散1に変換
標準化は、データを平均0、分散1に変換する方法です。
外れ値の影響を受けやすいですが、多くの機械学習アルゴリズムで効果的に機能します。
標準化は特に線形モデルやサポートベクターマシンなどの距離に基づくアルゴリズムで重要です。
標準化により、すべての特徴量が同じスケールになるため、モデルが各特徴量を公平に評価できるようになります。
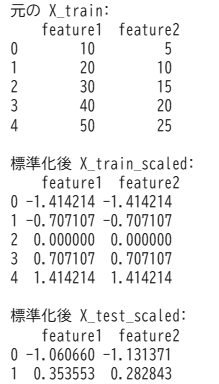
scikit-learnではStandardScalerクラスを使用します。
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
# サンプルのトレーニングデータ(5サンプル×2特徴量)
X_train = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [5, 10, 15, 20, 25]
})
# サンプルのテストデータ(2サンプル)
X_test = pd.DataFrame({
'feature1': [15, 35],
'feature2': [7, 17]
})
# 標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 結果の確認
print("元の X_train:\n", X_train)
print("\n標準化後 X_train_scaled:\n", pd.DataFrame(X_train_scaled, columns=X_train.columns))
print("\n標準化後 X_test_scaled:\n", pd.DataFrame(X_test_scaled, columns=X_test.columns))出力結果 ※Google Colabで表示
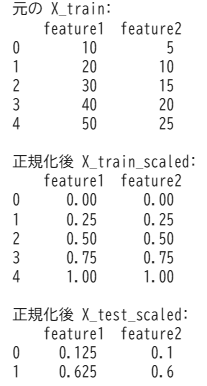
正規化(Normalization):0~1の範囲に変換
正規化は、データを0〜1の範囲に変換する方法です。画像処理や色の値などの扱いに適しています。
正規化はニューラルネットワークやk近傍法などのアルゴリズムで特に有効です。
データが特定の範囲に収まることで、勾配降下法などの最適化アルゴリズムが安定して動作します。
scikit-learnではMinMaxScalerクラスを使用します。
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# サンプルのトレーニングデータ(5サンプル×2特徴量)
X_train = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [5, 10, 15, 20, 25]
})
# サンプルのテストデータ(2サンプル)
X_test = pd.DataFrame({
'feature1': [15, 35],
'feature2': [7, 17]
})
# 正規化
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 結果の確認
print("元の X_train:\n", X_train)
print("\n正規化後 X_train_scaled:\n", pd.DataFrame(X_train_scaled, columns=X_train.columns))
print("\n正規化後 X_test_scaled:\n", pd.DataFrame(X_test_scaled, columns=X_test.columns))出力結果 ※Google Colabで表示
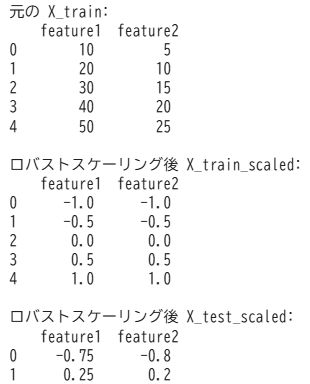
ロバストスケーリング(RobustScaler):外れ値の影響を抑えるスケーリング
外れ値が存在するデータセットでは、標準化や正規化が適切に機能しないことがあります。
ロバストスケーリングは、中央値と四分位範囲(IQR)を使用することで、外れ値の影響を抑えたスケーリングを実現します。
ロバストスケーリングは外れ値が多いデータセットや金融データなどの分析に特に有効です。
中央値と四分位範囲を使用するため、極端な値の影響を受けにくくなります。
scikit-learnではRobustScalerクラスを使用します。
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import RobustScaler
# サンプルのトレーニングデータ(5サンプル×2特徴量)
X_train = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [5, 10, 15, 20, 25]
})
# サンプルのテストデータ(2サンプル)
X_test = pd.DataFrame({
'feature1': [15, 35],
'feature2': [7, 17]
})
# ロバストスケーリング
scaler = RobustScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 結果の確認
print("元の X_train:\n", X_train)
print("\nロバストスケーリング後 X_train_scaled:\n", pd.DataFrame(X_train_scaled, columns=X_train.columns))
print("\nロバストスケーリング後 X_test_scaled:\n", pd.DataFrame(X_test_scaled, columns=X_test.columns))出力結果 ※Google Colabで表示
スケーリングの注意点
fit_transformは訓練データにのみ使用し、テストデータにはtransformのみを使用します。これは、テストデータを使ってスケーラーを学習してしまうと、モデルの評価が正しく行えなくなるためです(データリーク)。
全てのスケーリング手法が全てのアルゴリズムに有効とは限りません。たとえば、線形回帰やSVMは標準化に強く依存しますが、決定木やランダムフォレストはスケーリング不要です。
カテゴリ変数の処理
機械学習モデルの多くは、数値データを入力として受け取るため、カテゴリ変数(文字列などで表現されるデータ)を数値に変換する必要があります。
scikit-learnでは、以下の方法でカテゴリ変数を処理できます。
- ラベルエンコーディング
- オーディナルエンコーディング
- ワンホットエンコーディング
- ターゲットエンコーディング
ラベルエンコーディング(LabelEncoder):カテゴリ変数に整数値を割り当て
ラベルエンコーディングは、カテゴリカル変数に整数値を割り当てる手法の一つです。
カテゴリの出現順で自動的に番号を割り振るため、意図しない順序関係が生じる可能性があります。
# インポート
from sklearn.preprocessing import LabelEncoder
# カテゴリのラベル(繰り返しあり)
categories = ['low', 'medium', 'high', 'low', 'high', 'medium']
# ラベルを数値にエンコード
le = LabelEncoder()
encoded_categories = le.fit_transform(categories)
# 結果の確認
print("元のカテゴリ:", categories)
print("エンコード後:", encoded_categories)
label_map = {str(cls): int(le.transform([cls])[0]) for cls in le.classes_}
print("ラベルの対応:", label_map)出力結果 ※Google Colabで表示
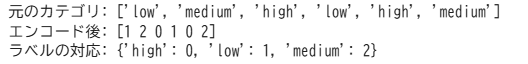
オーディナルエンコーディング(OrdinalEncoder):カテゴリ変数に順序を指定して整数値を割り当て
オーディナルエンコーディングはカテゴリ変数の順序を保持したまま、整数値を割り当てる手法です。
カテゴリ変数の順序は、デフォルトではアルファベット順で 0 から割り当てられます。順序を指定することも可能です。
# インポート
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# トレーニング用のデータ
X_train = pd.DataFrame({
'size': ['small', 'medium', 'large', 'small'],
'color': ['red', 'green', 'blue', 'green']
})
# テスト用のデータ(未知カテゴリを含む)
X_test = pd.DataFrame({
'size': ['extra_large', 'medium'],
'color': ['yellow', 'blue']
})
# カテゴリの順序を指定(明示的に)
categories = [
['small', 'medium', 'large'], # size列の順序
['blue', 'green', 'red'] # color列の順序
]
# OrdinalEncoderの設定
encoder = OrdinalEncoder(
categories=categories,
handle_unknown='use_encoded_value',
unknown_value=-1 # 未知カテゴリは -1 にする
)
# トレーニングデータに fit & transform
X_train_encoded = encoder.fit_transform(X_train)
# テストデータを transform
X_test_encoded = encoder.transform(X_test)
# 結果の表示
print("=== トレーニングデータ ===")
print(X_train)
print(pd.DataFrame(X_train_encoded, columns=X_train.columns))
print("\n=== テストデータ(未知カテゴリあり) ===")
print(X_test)
print(pd.DataFrame(X_test_encoded, columns=X_test.columns))出力結果 ※Google Colabで表示

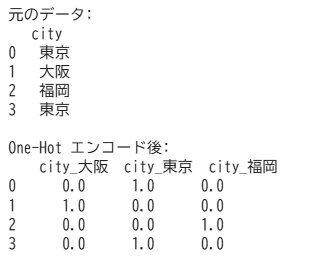
ワンホットエンコーディング(OneHotEncoder):順序のないカテゴリ変数を0/1のダミー変数に変換
「都道府県」「色」「職業」など、順序のないカテゴリ変数には、ワンホットエンコーディングを使用します。
カテゴリ変数を、0または1の値を持つダミー変数に変換します。
ワンホットエンコーディングを使うと、各カテゴリを独立した特徴量に分けることで、モデルが順序や大小関係を誤解しにくくなります。
# インポート
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# サンプルデータ
df = pd.DataFrame({'city': ['東京', '大阪', '福岡', '東京']})
# OneHotEncoder の設定
encoder = OneHotEncoder(sparse_output=False)
# エンコード実行
one_hot = encoder.fit_transform(df)
# DataFrameに変換
one_hot_df = pd.DataFrame(one_hot, columns=encoder.get_feature_names_out(['city']))
# 結果の確認
print("元のデータ:\n", df)
print("\nOne-Hot エンコード後:\n", one_hot_df)出力結果 ※Google Colabで表示
ターゲットエンコーディング:各カテゴリのターゲット変数の平均を用いる(リークに注意)
ターゲットエンコーディングは、各カテゴリに対して目的変数(ターゲット)の平均値を割り当てる方法です。
たとえば、カテゴリが「地域」、ターゲットが「売上」であれば、各地域ごとの平均売上を特徴量として使います。
ターゲットエンコーディングは、ターゲット変数の情報を使ってカテゴリ変数を変換するため、情報漏洩(リーク)のリスクがあります。
交差検証などを用いて、適切に評価を行う必要があります。
# インポート
import pandas as pd
# サンプルデータ
df = pd.DataFrame({
'地域': ['東京', '大阪', '福岡', '東京', '大阪'],
'売上': [100, 80, 90, 110, 70]
})
# 地域ごとの売上平均を計算(ターゲットエンコーディング)
region_mean = df.groupby('地域')['売上'].mean()
region_mean.name = '地域ごとの平均売上' # optional: Seriesに名前をつける
# エンコード列の追加
df['target_encoded'] = df['地域'].map(region_mean)
# 結果の確認
print("元のデータ + ターゲットエンコーディング:\n", df)出力結果 ※Google Colabで表示

パイプライン
機械学習のワークフローにおいて、データの前処理から特徴量エンジニアリング、モデル学習までを一つのプロセスとして統合する仕組みがパイプライン(Pipeline)です。
パイプラインの主なメリットは以下のとおりです。
- データ処理の自動化
- コードの簡潔化
- 交差検証(クロスバリデーション)の容易な実装
- モデル再現性の向上
scikit-learnのパイプラインは、Pipeline クラスを使って定義します。以下のような構文で作成できます。
# インポート
from sklearn.pipeline import Pipeline
# パイプライン
pipeline = Pipeline(steps)stepsには、処理のステップを定義するリストを入力します。
Pipeline(steps=[('名前1', 変換器1), ('名前2', 変換器2), …, ('名前N', 最終モデル)])各ステップは(‘名前’, 変換器)のタプルで指定します。名前は任意の文字列で大丈夫です。
リストの順序通りにステップが実行されます。
# インポート
import numpy as np
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# サンプルデータの作成(2クラス分類)
np.random.seed(42) # 再現性
X = pd.DataFrame({
'feature1': np.random.normal(0, 1, 100),
'feature2': np.random.normal(5, 2, 100)
})
y = np.random.choice([0, 1], size=100) # ラベルは0 or 1
# 訓練・テストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# パイプラインの作成
pipeline = Pipeline(steps=[
('scaler', StandardScaler()), # データの標準化
('classifier', LogisticRegression()) # ロジスティック回帰モデル
])
# モデルの学習
pipeline.fit(X_train, y_train)
# 予測
predictions = pipeline.predict(X_test)
# 結果の確認
print("予測結果:", predictions)出力結果 ※Google Colabで表示
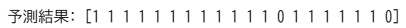
この例では、まずStandardScalerで特徴量を標準化し、その後LogisticRegressionで分類を行う流れを構築しています。
scikit-learnで使用できる主なアルゴリズム
scikit-learnでは様々なアルゴリズムを使用することができます。
公式サイトで使用できるアルゴリズムを確認できます。
ここでは、主なアルゴリズムを紹介します。
ロジスティック回帰(Logistic Regression)
ロジスティック回帰は、分類問題において最も基本的かつ汎用的なアルゴリズムです。Yes/Noのような二値分類に強みを発揮します。
- 解釈性が高い
- 過学習しにくい
- 高次元データにはやや弱い
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)決定木(Decision Tree)
決定木は、データを木構造で分割していく手法で、直感的に理解しやすいのが特徴です。
- 可視化しやすい
- ノンパラメトリックで前提が少ない
- 過学習しやすいため、剪定が重要
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)ランダムフォレスト(Random Forest)
ランダムフォレストは複数の決定木を使ったアンサンブル学習の一種です。
- 高い精度を実現しやすい
- 過学習に強い
- 学習・予測コストはやや高め
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)勾配ブースティング決定木(Gradient Boosting)
勾配ブースティング(Gradient Boosting Decision Tree:GBDT)は、予測誤差を徐々に修正するようにモデルを強化していく手法です。
- 精度が非常に高い
- パラメータ調整が重要
- 学習時間が長くなる場合がある
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier()
model.fit(X_train, y_train)k近傍法(k-Nearest Neighbors)
k近傍法(k-NN)は、最も近いk個のデータを参照して分類を行うシンプルなアルゴリズムです。
- 実装が簡単
- 学習コストは低いが、予測時の計算量が多い
- 外れ値に弱い
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)サポートベクターマシン(Support Vector Machine)
SVM(サポートベクターマシン)は、データを線形・非線形に分類する強力なアルゴリズムです。
- マージン最大化により高精度
- 小規模データに強い
- データ量が多いと遅くなる
from sklearn.svm import SVC
model = SVC()
model.fit(X_train, y_train)ナイーブベイズ(Naive Bayes)
ナイーブベイズは、ベイズの定理に基づいた確率的な分類器で、特にテキスト分類において高い精度を発揮します。
- シンプルかつ高速
- 独立性の仮定が前提
- 精度は用途によって異なる
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)scikit-learnのテクニック
モデルの選び方
scikit-learnには、様々な機械学習モデルが用意されています。
どのモデルを選ぶべきかは、解決したい問題の種類(分類、回帰など)やデータの特性によって異なります。
| タスク | モデル例 | モデル名(scikit-learn) |
|---|---|---|
| 分類 | 決定木、ランダムフォレスト、SVM | DecisionTreeClassifier、RandomForestClassifier、SVC |
| 回帰 | 線形回帰、勾配ブースティング | LinearRegression、GradientBoostingRegressor |
| クラスタリング | K-means、DBSCAN | KMeans、DBSCAN |
scikit-learnの公式ドキュメント には、問題の種類に応じたモデル選択のフローチャートが掲載されていますので、参考にしてください。
精度向上のためのハイパーパラメータ調整
多くの機械学習モデルには、ハイパーパラメータと呼ばれる、モデルの学習方法を制御するパラメータがあります。
ハイパーパラメータを適切に調整することで、モデルの性能を向上させることができます。
GridSearchCV(グリッドサーチ)
指定した範囲のハイパーパラメータの組み合わせを全て試し、最も良い性能を示す組み合わせを探索します。
# インポート
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
# サンプルデータ作成(100件×2特徴量のバイナリ分類)
np.random.seed(42)
X = pd.DataFrame({
'feature1': np.random.randn(100),
'feature2': np.random.rand(100) * 10
})
y = np.random.choice([0, 1], size=100)
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ハイパーパラメータの候補を指定
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20]
}
# グリッドサーチ設定
grid_search = GridSearchCV(RandomForestClassifier(), param_grid, cv=5)
# 学習
grid_search.fit(X_train, y_train)
# 最良のパラメータを出力
print("Best parameters:", grid_search.best_params_)
print("Best score (cross-validated accuracy):", grid_search.best_score_)出力結果 ※Google Colabで表示

RandomizedSearchCV(ランダムサーチ)
指定した範囲からランダムにハイパーパラメータの組み合わせを選び、探索します。GridSearchCVよりも計算コストが低い場合があります。
チューニング後のモデル使用方法
GridSearchCV や RandomizedSearchCV でハイパーパラメータチューニングしたモデルはbest_estimator_に格納されています。
# 最良のパラメータを使ったモデル
best_model = grid_search.best_estimator_
# 予測
y_pred = best_model.predict(X_test)GridSearchCV や RandomizedSearchCVで使用できるプロパティ、メソッドは次の通りです。
| プロパティ / メソッド | 説明 |
|---|---|
| .best_estimator_ | 最良のパラメータで訓練されたモデル ハイパーパラメータチューニング後はこれを使用する |
| .best_params_ | 最良モデルのパラメータ辞書 |
| .best_score_ | クロスバリデーションでの最高スコア |
| .cv_results_ | 全試行結果(スコアやパラメータなどを含む辞書) |
精度を可視化するためのビジュアライゼーション手法
学習したモデルがどの程度の精度を出すことができるのか、可視化して確認することができます。
精度の可視化方法は次の方法があります。
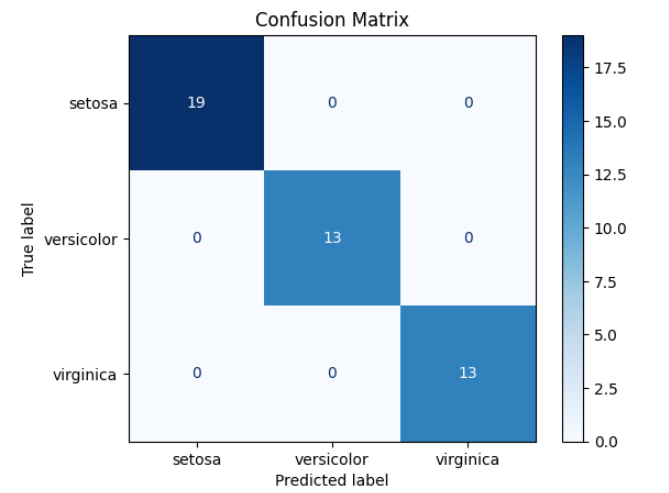
- 混同行列(Confusion Matrix)
- 分類問題において、モデルが正しく分類できたデータと誤って分類したデータをクラスごとに集計した表です。
- ROC曲線とAUC
- 学習曲線(Learning Curve)
- 学習データのサイズを変化させたときの、学習データとテストデータに対するスコアの変化を表すグラフです。モデルが過学習しているか、学習不足であるかを判断するのに役立ちます。
- 特徴量の重要度(Feature Importance)
- 決定木ベースのモデル(決定木、ランダムフォレストなど)では、各特徴量がモデルの予測にどれだけ貢献したかを示す指標です。
混同行列の可視化サンプルコード
# インポート
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Irisデータセットを読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# ランダムフォレストで分類
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 混同行列を作成・可視化
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=iris.target_names)
disp.plot(cmap="Blues")
plt.title("Confusion Matrix")
plt.show()出力結果 ※Google Colabで表示
scikit-learnを使う際の注意点
過学習を防ぐための方法
過学習とは、モデルが訓練データに対して過剰に適合しすぎてしまい、未知のデータに対しては精度が下がってしまう状態のことです。
scikit-learnで機械学習モデルを構築する際、以下の方法で過学習を防ぐことができます。
- 交差検証(クロスバリデーション)
- 正則化
交差検証(クロスバリデーション)
データを複数のグループに分割し、一部を検証用、残りを学習用として、複数回学習と評価を繰り返すことで、モデルの汎化性能を評価します。
scikit-learnにはcross_val_score関数が用意されています。
# インポート
from sklearn.model_selection import cross_val_score
# 交差検証を使用してモデルの性能を評価
scores = cross_val_score(model, X, y, cv=5)正則化
モデルの複雑さにペナルティを課すことで、過剰な学習を抑制します。
ロジスティック回帰の場合は、Cパラメータ(正則化の強度)を調整します。
Cが小さいほど正則化が強くなります。
# インポート
from sklearn.linear_model import Ridge, Lasso
# L2正則化(Ridge)
ridge_model = Ridge(alpha=1.0)
# L1正則化(Lasso)
lasso_model = Lasso(alpha=0.1)関数を複数回実行した際のデータ上書きリスク
scikit-learnを使った機械学習の実装では、前処理や特徴量エンジニアリング、モデル学習といった複数の処理ステップが存在します。
その過程で同じ変数名を使い続けることによる「データの上書き」がバグや精度低下を引き起こすことがあります。
NG例
X = scaler.fit_transform(X)
X = select_k_best_features(X, y)
X = pca.transform(X)変数名を分ける
対策としては、処理ステップごとに変数名を分ける方法があります。
対策
X_scaled = scaler.fit_transform(X)
X_selected = select_k_best_features(X_scaled, y)
X_pca = pca.transform(X_selected)パイプラインを活用する
scikit-learnのパイプラインを使用することで、データ処理とモデル学習をひとつのまとまりとして管理できます。
パイプラインの例
# インポート
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression())
])
pipeline.fit(X_train, y_train)おすすめの学習方法
書籍で基礎を学ぶ
最初は、信頼できる書籍を使って体系的に学ぶのがおすすめです。
特に以下のような書籍が評価が高く、scikit-learnを使った実装例も豊富です。


オンラインスクールで広く学ぶ
scikit-learnを学習するためのおすすめスクールはキカガクの長期コースです。
キカガクのオンライン講座は、動画で視覚的に学べるのが特長です。
長期コースでは機械学習・ディープラーニング・データ分析まで広くカバーされており、scikit-learnを使った演習も含まれています。
学習ステップが丁寧で、未経験者でもつまずきにくい構成です。
キカガクについては、こちらの記事で解説しています。
⇒ 【徹底解説】キカガク長期コースはdodaと提携した転職おすすめのオンラインスクール!
\ 最大80%給付!30秒で申し込み/
キカガク公式HPに飛びます
Kaggleで実践的に学ぶ
学んだ知識をアウトプットするには、「Kaggle(カグル)」への参加がおすすめ。
Kaggleはデータ分析の世界的なコンペサイトで、scikit-learnを使った分析例も豊富にあります。
他の参加者のコードを読むだけでも非常に勉強になりますし、自分のコードを投稿してフィードバックを得ることで、実力が一気に伸びます。
Q&A
scikit-learnって何ができるの?
Pythonで機械学習を簡単に使えるようにするライブラリです。
分類・回帰・クラスタリングなど、いろんなアルゴリズムが使えます。
データの前処理やモデルの評価もできます。scikit-learnを使うには、どんなPythonの知識が必要?
Pythonの基本的な文法(変数、データ型、リスト、辞書、if文、for文など)が必要です。
NumPy(数値計算ライブラリ)やpandas(データ分析ライブラリ)を使用する頻度が高いので、基本的な使い方を学習することをオススメします。Pythonの基本的な文法については、こちらの記事で解説しています。
⇒ 【初心者必見】これだけでOK!Pythonの基本文法をわかりやすく解説NumPyについては、こちらの記事で解説しています。
⇒ NumPyの使い方をわかりやすく解説!!配列を使いこなそう!サンプルコード付き!pandasについては、こちらの記事で解説しています。
⇒ pandasの使い方をわかりやすく解説!!データフレームを使いこなそう!サンプルコード付き!データを「学習用」と「テスト用」に分けるのはなぜ?
モデルが本当に使えるかどうかを確かめるために、データを「学習用」と「テスト用」に分けます。
学習用データでモデルを訓練し、テスト用データでモデルを評価します。
まとめ
この記事では、scikit-learnの基本的な使い方から、データ前処理、モデル構築、評価までの実践的な流れについて、わかりやすく解説しました。
scikit-learnは、機械学習の初心者から専門家まで幅広く使われているライブラリです。
一見難しそうですが、基本手順を1つ1つ進めていけば、スムーズに機械学習を実行することができます。
記事内のサンプルコードを参考にして、いろいろ試してください。
Pythonを効率的に学習するために
Pythonの学習方法は、書籍やyoutube、スクールなどがありますが、一番のおすすめはオンラインスクールでの学習です。
オンラインスクールを勧める理由は以下の通り。
- 学習カリキュラムが整っているので、体系的に学ぶことができる。
- 時間や場所を選ばずに、自分のペースで学習できる。
- 学習で詰まったときに、気軽に質問できる環境がある。
オンラインスクールについてはコチラの記事で紹介しています。
⇒ これで決まり!Pythonオンラインスクール おすすめ3社を厳選!
2024年10月1日から給付制度が拡充され、最大80%給付されるスクールもあります。
Python学習を効率的に進めるために、スクールの検討をしてみてください。
おすすめオンラインスクール
コスト重視:デイトラ![]()
AIスキル重視:Aidemy PREMIUM ![]()
転職重視:キカガク![]()
最後まで読んでいただきありがとうございます!
ご意見、ご感想があれば、コメントを頂けるとうれしいです!!
